こんにちは,Ridge-iの@obaradsです.本記事では,Image2Point: 3D Point-Cloud Understanding with Pretrained 2D ConvNets [Xu et al, 2021]を紹介します(こちらの論文ではNeural Collapseについても取り扱っていますが,長くなるため今回は省きます).
はじめに
ロボティクスや自動運転などの分野では,点群と呼ばれるデータが扱われることがあります.点群は,LiDARをはじめとする深度センサーから取得することが可能であり,取得された点群は3Dマップやセグメンテーションなどに利用されます.近年では,点群を深層学習モデルに入力して点群に対するセマンティックセグメンテーション[Hu et al, 2020]や物体検出[Qi et al, 2019]を行う手法も提案されています.点群深層学習技術の発展により下図の規模のデータを扱うコンペ[Hu et al, 2021]も開かれていることから,点群と深層学習に注目が集まっていることがわかります.

しかしながら,以前の表現学習の記事でも触れた様に深層学習手法で必要とされる点群データセットの作成には膨大な時間と費用がかかってしまいます. 点群データセットが高価である以上,下流タスクの精度を安定して得ることが困難であることが考えられます.これらを克服する可能性を持つアイデアとして,他の表現で学習された深層学習モデルを点群の深層学習モデルへ利用するというものがあります.その一例として,今回はImage2Point: 3D Point-Cloud Understanding with Pretrained 2D ConvNets [Xu et al, 2021]を紹介します.尚,本記事では訓練可能なパラメータを「パラメータ」と書きます.
なぜ2D画像の学習済みモデル及び知識を3D点群深層学習モデルへ利用するのか
直観的には,2D画像も3D点群も物理空間上での視覚表現として扱うことが可能であり,視覚的概念も同じです.また,人はどちらの表現も認識することが可能です.著者らはこれらの背景に基づいて,実際に2D画像で学習されたモデルが点群を認識できるかどうか検証します.具体的には,2D画像で事前学習されたモデルの事前学習済みパラメータを3D点群深層学習モデルに転移し,ファインチューニングなどを介して3D点群を理解することができるか検証します.
また,これらの転移による点群処理における利点も存在し,ダウンストリームタスクのパフォーマンス改善や少量のデータ使用時における精度改善などが挙げられます.これらも以前の表現学習の記事で示した様に,ラベル付きデータが限られた状態で役に立つ利点だと言えます.
検証の方針
著者らは,検証を行うにあたって4つの疑問に従った実験を設けました.実験は以下の通りです.
- 転移された事前学習済み画像深層学習モデルは点群を認識できるか?
- 画像を用いた事前学習は点群認識の性能向上につながるか?
- 点群認識におけるデータ効率の向上は可能であるか?
- 画像事前学習によって点群深層学習モデルの学習を早められるか?
本実験では,ResNet [He et al, 2016]から3Dスパース畳み込み[Choy et al, 2019]へのファインチューニングを主に行います.ただし,2番目の実験のみ他のモデルも使います.
ResNetから3Dスパース畳み込みモデルへの事前学習済みパラメータの転移の概要は以下の図内にあるVoxel-based Point-cloud modelの通りです.後ほど説明する2D畳み込みを3Dスパース畳み込みへ拡張して転移する以外,バッチ正規化層や活性化層などをそのまま転移します.転移された後のモデルには,タスクに合わせた追加の入力及び出力層が付きます.また,前述したように他のモデルを利用した2番目の実験は,図内のProjection-based Point-cloud modelやTransformer Point-cloud modelのように学習済みパラメータをそのまま転移します.

2D畳み込みから3D畳込みへの拡張
実験では,3Dスパース畳み込み機構への学習済みパラメータの転移を行います.本実験における3Dスパース畳み込みを持ったモデルの概要は以下の通りです.
- 扱うデータは各点が3D座標値を持った点群であり,その点群はオプションでRGB値などを持つ.
- モデルに入力する際に点群は座標値に従ってボクセル化/量子化される.各ボクセルではボクセル内に複数の点があった場合,全ての点の特徴から平均をとり,その平均値をボクセルの特徴に割り当てる.点が無いボクセルは空のボクセルとして扱われ,空の場合にスパース畳み込み時の計算はスキップされる.
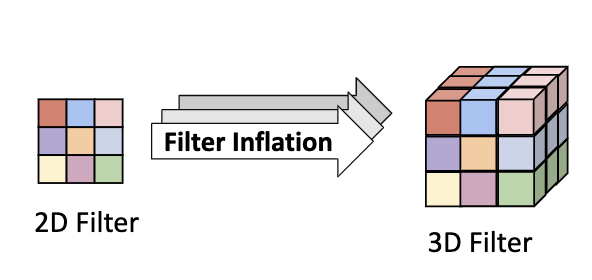
このような3Dスパース畳み込みモデルは,$K$がフィルタのサイズであるとき,層ごとに$[K,K,K]$のフィルタを持ちます.2D畳み込みは$[K, K]$を持つため,2D畳込みから3Dスパース畳込みへの転移では,フィルタに対して一次元分の拡張が必要となります.拡張のシンプルな方法としては,以下の図の左に示すような,拡張する次元方向への複製[Carreira, 2017]が挙げられます.本実験では,このシンプルな手法を採用します.
実験
使用するデータセット
使用するデータセットは以下のようになります.事前学習用のデータセットと,事前学習の効果を確認するためのターゲットタスクのデータセットがあります.基本的にはImageNetデータセットを事前学習用のデータセットとして扱い,ModelNet 3D Warehouseを転移後のモデルの評価データセットとして扱います.
| データセット名 | 利用場面 | 利用するタスク | 補足 |
|---|---|---|---|
| ModelNet 3D Warehouse [Wu et al, 2015] | 転移後のモデル評価 | 分類 | CADデータであるため,点群を別途生成 |
| S3DIS [Armeni et al, 2017] | 転移後のモデル評価 | セグメンテーション | 屋内データ |
| SematicKITTI [Behley et al, 2019] | 転移後のモデル評価 | セグメンテーション | ドライブで撮影した屋外データ |
| ImageNet-21K [Deng et al, 2009] | 事前学習 | 分類 | 自然物の画像 |
| ImageNet-1K [Deng et al, 2009] | 事前学習 | 分類 | ImageNet-21Kのサブセット |
| Tiny-ImageNet [Deng et al, 2009] | 事前学習 | 分類 | ImageNet-21Kのサブセット |
| FractalDB [Kataoka et al, 2020] | 事前学習 | 分類 | 非自然物の画像 |
| Cityscapes [Cordts et al, 2016] | 事前学習 | セグメンテーション | ドライブで撮影した屋外データ |
モデルと学習の比較
利用するモデルは以下のようになります.基本的には事前学習済みのResNetを3Dスパース畳み込みモデル(3D Sparse ConvNets)に適用し,そのモデルの性能評価を行うという形式になります.他の手法は,実験2で使用されます.
| モデル名 | 補足 |
|---|---|
| ResNet [He et al, 2016] | 事前学習用のモデルとして利用 |
| 3D Sparse ConvNets [Choy et al, 2019] | ResNetのパラメータの転移先となるモデル |
| SimpleView [Goyal et al, 2021] | ResNetのパラメータの転移先となるモデル |
| HRNetV2-W48 [Sun et al, 2019] | 事前学習用のモデルとして利用 |
| ViT [Dosovitskiy et al, 2020] | 事前学習及び転移後のモデルとして利用 |
| PointNet++ [Qi et al, 2017] | 事前学習及び転移後のモデルとして利用 |
また,本実験ではファインチューニングする対象を変えて比較するため,以下の単語を定義します.
| 名称 | 意味 |
|---|---|
| FIP-ALL | ネットワーク全体のファインチューニング |
| FIP-IO+BN | 入力層及び出力層,バッチ正規化層のファインチューニング |
| FIP-IO | 入力層及び出力層のみをファインチューニング |
1. 転移された事前学習済み画像深層学習モデルは点群を認識できるか?
この実験では,2次元画像による事前学習済みパラメータを用いることで,3次元点群に対するタスクでも有意な結果が得られるか確認します.そのため,ここではFIP-IOもしくはFIP-IO+BNを行うだけで,最初から学習する場合の結果に近いもしくは超えることを想定します.前述したように,画像で訓練されたResNetの畳み込みを3Dスパース畳み込みに変換し,そのまま点群処理タスクに利用します.実験の結果は以下の表の通りです.
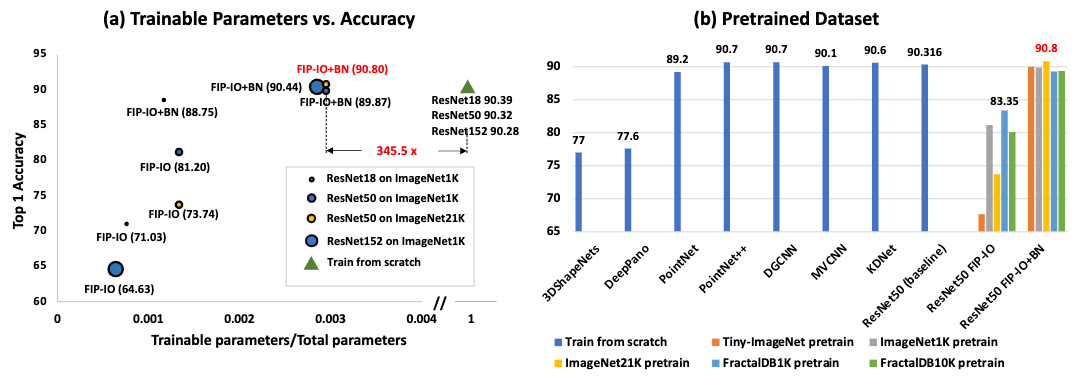
図の左側はTop1精度とファインチューニングする訓練可能なパラメータの割合の関係を示しています.ResNet50を利用した場合,入出力層をファインチューニング(FIP-IO)を行うだけでも81.20%の精度が得られることが確認できました.また,画像による事前学習済みのパラメータを利用した場合,全体のパラメータの0.3%に対するファインチューニングだけでも初めから学習させるより良い結果を出すことが実験で確認されました.
さらに著者らはデータセットを変えた場合の結果も示しました.結果は上の図の右側に示す通りであり,FractalDBのような非自然画像でもImageNetの事前学習結果に届くほどの精度を得ることが確認されました.
2. 画像を用いた事前学習は点群認識の性能向上につながるか?
本実験では,画像表現を用いた事前学習が他の点群深層学習モデルのパフォーマンス向上の役に立つか調査します.本実験では,3Dスパース畳み込み,点ベース点群深層学習のPointNet++,投影ベースのSimpleView,変換に基づく手法であるViTに対して画像を用いた事前学習を行います.
3Dスパース畳み込み,SimpleView及びViTは事前学習済みのモデルを利用します.ただし,PointNet++では点群と同じ[点の数, 座標値を含むチャンネル数]の形式に一致する入力を必要とします.そのため,画像をピクセル位置に基づく点群に変換した後に事前学習を行っています.実験はFIP-ALLで行い,その結果は以下の通りです.
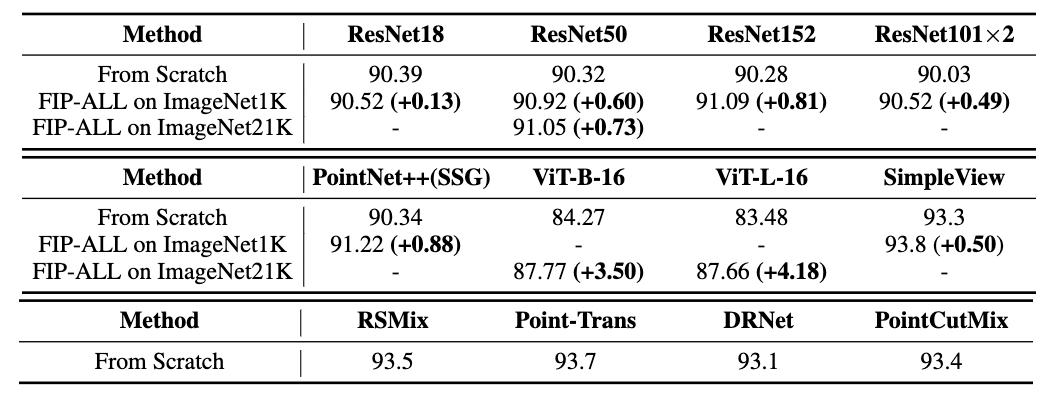
ModelNet 3D Warehouseのタスクでは,すべてのモデルにおいて初めから学習する場合よりも精度が改善する傾向が見られました.
またセグメンテーションタスクにおいても,下の表に示すように改善の傾向が見られました.

3. 点群認識におけるデータ効率の向上は可能であるか?
この実験では,転移後のモデルの訓練時に利用する訓練データ量を調節します.ImageNet-1Kを用いて事前学習されたResNetを3Dスパース畳み込みモデルに転移させ,ModelNetからランダムに選ばれた点群データのみで3Dスパース畳み込みモデル全体のパラメータを学習させてテストを行います.結果は以下の通りとなります.

結果が示すように,訓練データの量が限られている状態では事前学習が有効であることが確認されました.特に非常に訓練データの量が限られている場合に有効であるものの,使用することができるデータの量が増えていくにつれてメリットがわずかになる傾向があることが確認されました.
また,自己教師あり学習を用いた半教師あり学習の先行研究[Chen et al, 2020]に触発され,これに基づく実験を行いました.こちらではModelNet 3D Warehouseによる評価でPointContract[Xie et al, 2020]の事前学習済みモデルを用いた手法との比較を行なっており,以下の表に示すようImageNet-1Kを利用した事前学習手法が良好な結果を示しました.

4. 画像事前学習によって点群深層学習モデルの学習を早められるか?
本実験では,画像事前学習済みパラメータを点群深層学習モデルの学習の初期値に用いることで学習の高速化が可能であるか調査しました.この実験ではModelNet 3D Warehouseを学習に用いており,その結果は下図の通りになります.
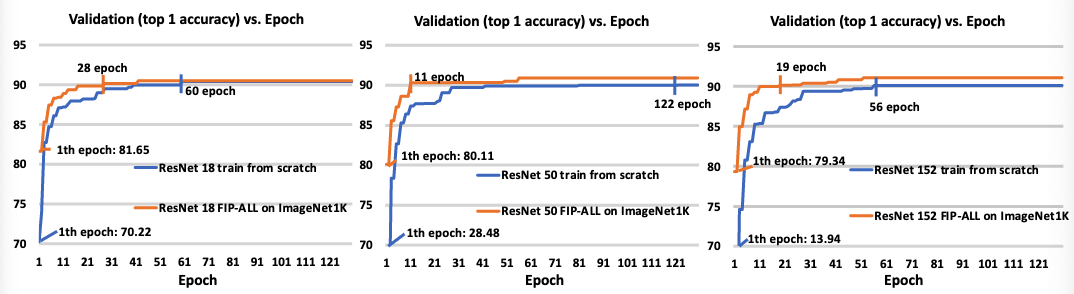
図はResNetの種類ごとに示されており,バリデーションの精度が90%に辿り着くまでの比較を行なっています.どのモデルでも画像による事前学習を用いた手法の方が早く90%の精度に辿り着いており,学習の高速化が可能であることを示しました.
最後に
今回は2D画像による事前学習モデルを3D畳み込みモデルへ転移する手法及び実験を紹介しました.近年では,他の表現を利用した(マルチモーダルな)事前学習がいくつか提案されています.今回の様な2Dの知識を用いた3Dモデルの学習手法[Liu et al, 2021][Afham et al, 2022]についてもありますが,3Dモデルから2Dモデルへの事前学習手法もあります[Hou et al, 2021][Liu et al, 2021].これらの研究が進むことで,データの制限への対処法がより明確になってゆくと思われます.
参考文献
- Xu, Chenfeng, Shijia Yang, Bohan Zhai, Bichen Wu, Xiangyu Yue, Wei Zhan, Peter Vajda, Kurt Keutzer, and Masayoshi Tomizuka. 2021. “Image2Point: 3D Point-Cloud Understanding with Pretrained 2D ConvNets.” arXiv [cs.CV] . arXiv. http://arxiv.org/abs/2106.04180.
- Hu, Qingyong, Bo Yang, Linhai Xie, Stefano Rosa, Yulan Guo, Zhihua Wang, Niki Trigoni, and Andrew Markham. 2020. “RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds.” In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . IEEE. https://doi.org/10.1109/cvpr42600.2020.01112.
- Qi, Charles R., Or Litany, Kaiming He, and Leonidas J. Guibas. 2019. “Deep Hough Voting for 3d Object Detection in Point Clouds.” In Proceedings of the IEEE/CVF International Conference on Computer Vision , 9277–86. openaccess.thecvf.com.
- Hu, Qingyong, Bo Yang, Sheikh Khalid, Wen Xiao, Niki Trigoni, and Andrew Markham. 2021. “Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges.” In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . IEEE. https://doi.org/10.1109/cvpr46437.2021.00494.
- Choy, Christopher, Junyoung Gwak, and Silvio Savarese. 2019. “4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks.” In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . IEEE. https://doi.org/10.1109/cvpr.2019.00319.
- Carreira, Joao, and Andrew Zisserman. 2017. “Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . IEEE. https://doi.org/10.1109/cvpr.2017.502.
- Wu, Zhirong, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 2015. “3d Shapenets: A Deep Representation for Volumetric Shapes.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 1912–20.
- Armeni, Iro, Sasha Sax, Amir R. Zamir, and Silvio Savarese. 2017. “Joint 2D-3D-Semantic Data for Indoor Scene Understanding.” arXiv [cs.CV] . arXiv. http://buildingparser.stanford.edu/images/2D-3D-S_2017.pdf.
- Behley, Jens, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. 2019. “Semantickitti: A Dataset for Semantic Scene Understanding of Lidar Sequences.” In Proceedings of the IEEE/CVF International Conference on Computer Vision , 9297–9307.
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep Residual Learning for Image Recognition.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . IEEE. https://doi.org/10.1109/cvpr.2016.90.
- Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. “ImageNet: A Large-Scale Hierarchical Image Database.” In 2009 IEEE Conference on Computer Vision and Pattern Recognition , 248–55.
- Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. 2016. “The Cityscapes Dataset for Semantic Urban Scene Understanding.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . IEEE. https://doi.org/10.1109/cvpr.2016.350.
- Kataoka, Hirokatsu, Kazushige Okayasu, Asato Matsumoto, Eisuke Yamagata, Ryosuke Yamada, Nakamasa Inoue, Akio Nakamura, and Yutaka Satoh. 2021. “Pre-Training Without Natural Images.” In Computer Vision – ACCV 2020 , 583–600. Lecture Notes in Computer Science. Cham: Springer International Publishing.
- Qi, Charles R., Li Yi, Hao Su, and Leonidas J. Guibas. 2017. “PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space.” arXiv [cs.CV] . arXiv. http://arxiv.org/abs/1706.02413.
- Sun, Ke, Bin Xiao, Dong Liu, and Jingdong Wang. 2019. “Deep High-Resolution Representation Learning for Human Pose Estimation.” arXiv [cs.CV] . arXiv. http://arxiv.org/abs/1902.09212.
- Chen, Ting, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey Hinton. 2020. “Big Self-Supervised Models Are Strong Semi-Supervised Learners.” arXiv [cs.LG] . arXiv. http://arxiv.org/abs/2006.10029.
- Goyal, Ankit, Hei Law, Bowei Liu, Alejandro Newell, and Jia Deng. 18--24 Jul 2021. “Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline.” In Proceedings of the 38th International Conference on Machine Learning, edited by Marina Meila and Tong Zhang, 139:3809–20. Proceedings of Machine Learning Research. PMLR.
- Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, et al. 2020. “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale.” arXiv [cs.CV]. arXiv. http://arxiv.org/abs/2010.11929.
- Xie, Saining, Jiatao Gu, Demi Guo, Charles R. Qi, Leonidas Guibas, and Or Litany. 2020. “PointContrast: Unsupervised Pre-Training for 3D Point Cloud Understanding.” In Computer Vision – ECCV 2020, 574–91. Springer International Publishing.
- Liu, Yueh-Cheng, Yu-Kai Huang, Hung-Yueh Chiang, Hung-Ting Su, Zhe-Yu Liu, Chin-Tang Chen, Ching-Yu Tseng, and Winston H. Hsu. 2021. “Learning from 2D: Pixel-to-Point Knowledge Transfer for 3D Pretraining.” arXiv [cs.CV]. arXiv. http://arxiv.org/abs/2104.04687.
- Afham, Mohamed, Isuru Dissanayake, Dinithi Dissanayake, Amaya Dharmasiri, Kanchana Thilakarathna, and Ranga Rodrigo. 2022. “Crosspoint: Self-Supervised Cross-Modal Contrastive Learning for 3d Point Cloud Understanding.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9902–12.
- Hou, Ji, Saining Xie, Benjamin Graham, Angela Dai, and Matthias Nießner. 2021. “Pri3D: Can 3D Priors Help 2D Representation Learning?” arXiv [cs.CV]. arXiv. http://arxiv.org/abs/2104.11225.
- Liu, Zhengzhe, Xiaojuan Qi, and Chi-Wing Fu. 2021. “3D-to-2D Distillation for Indoor Scene Parsing.” In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE. https://doi.org/10.1109/cvpr46437.2021.00444.