こんにちは, Ridge-iの@hide24563630 です. 本記事では, 画像から得られる情報を点群の処理に活用する研究を追試した結果を紹介します. また, 本記事はtancoro3にレビューしていただきました.
はじめに
3次元の物体認識やセグメンテーションは, 自動運転における周辺認識[1]や, スマートシティ計画・管理に必要不可欠である大規模都市3次元モデリング[2, 3]など, 幅広い分野で実用化が求められています. 特に, 近年目覚ましい発展を続けている自動運転の分野では, 人間のドライバーの手助けなしでコンピュータが自動車の周囲の環境を理解して安全に運転するアプローチの一つとして, Light Detection and Ranging (LiDAR) という3Dレーザースキャナーを用いて周囲の環境を3次元データとして取得したのちに, その3次元データから車両や歩行者を検出しています[1]. LiDARで取得される3次元データ (図1の上図 ) は一般的に点群 (Point Cloud Data) と呼ばれており, その点群上で物体認識を行う手法の研究は盛んに行われています. 画像ではなくあえて点群を使用する理由の一つは, LiDARと物体との正確な距離が測定されたデータだからです. 画像の中には, カメラと物体との距離である深度情報も持つRGB-D画像も存在しますが, 距離の正確性という観点では点群には及ばないというのが現状です. そのため, 歩行者や車両などといった物体との距離が非常に重要である分野では, しばしば点群を用いた3次元物体認識に取り組んでいます.
しかし, 点群上で物体認識を行う3次元物体認識手法の進歩は日進月歩であるものの, 2次元の画像を対象とする画像認識手法に比べると未だ発展途上の段階です[5]. 画像認識手法に比べて3次元物体認識手法の発展が遅れている原因の一つとして挙げられるのは, 図1に示すように, 点群は画像よりも複雑なデータであるのにも関わらず, 画像に比べて非常に疎 (スパース) なデータであるからです[5].
その問題を解決するアプローチとしてしばしば行われるのは, 画像から得られる情報を用いて点群のスパースな情報を補うことで, 点群上での物体認識性能を向上させるというアプローチです[6, 7, 8]. 今回は, CVPR2020で採択されたPointPainting [6]の追試を行うことで, 画像から得られる特徴量を活用することで点群上での物体認識性能を本当に高められるのか検証しました.

点群の特徴量の増やし方
今回行う実験では, 入力データに対して2段階の処理を行うことで3次元の物体検出やセマンティックセグメンテーションを行います (図2). 入力データは, 通常の点群のほかに, 同じカメラ視点で撮影されたRGB画像や, RGB画像中のどこに車などの物体が存在するかを推定した擬似ラベルです. この擬似ラベルは, 既存の画像認識手法を用いて機械的に推定することで得られたものです. 前処理では, これらの画像や擬似ラベル, 点群を扱いやすい形に変換します. そうして得られた前処理済みのデータに対して既存の点群処理手法を適用することで物体検出やセマンティックセグメンテーションを行います. 各処理の詳細は順を追って説明します.

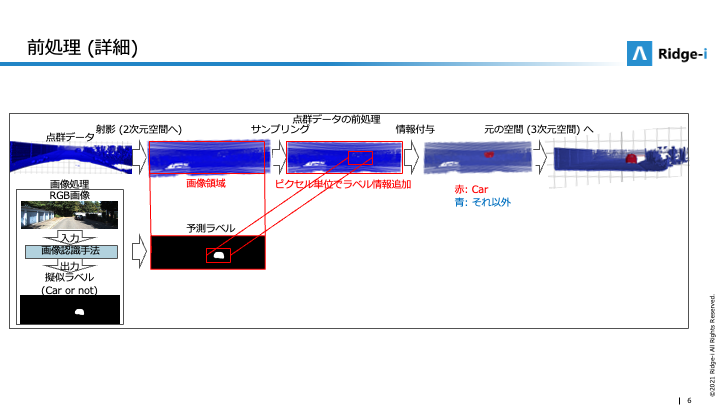
まずは入力データの前処理について説明します (図3). 入力データの前処理では, 点群の各点と画像 (あるいは擬似ラベル) の関連付けを行うことで, 各点が持つ特徴量を増やします. 例えば, 図3では, 擬似ラベルの各ピクセルに含まれる情報と点群の各点の対応付けを行うことで, この赤く塗られた点は車を撮影したものである可能性が高いという情報を追加しました. 各点の特徴量として点のXYZ座標だけでなく, RGB値や意味情報を扱えるようになるため, 点群処理の精度をより向上できると考えられます.

今回行う実験では, 図4に示すように, 擬似ラベルをRGB画像から生成 (画像処理) し, 擬似ラベルや画像のRGB値を点群の各点に対応付ける (点群の前処理) ことで点群の特徴量を増やします. 点群の前処理では, まず, この3次元空間上の点群を画像と同じ2次元空間へ射影します. これは, カメラのキャリブレーション情報などを用いて行います. 続いて, 射影された点群のうち, 画像の領域と対応する領域を切り取ることで画像と対応関係がある点をサンプリングします. サンプリングされた点群では, 各点と画像のピクセルの位置関係は対応が取れていると仮定しています. その後, 擬似ラベルの各ピクセルに含まれる情報を対応する点群上の点の特徴量とすることで, RGB画像から得られる情報 (特徴量) を点群に射影します. このようにして得られた擬似ラベル付きの点群を既存の点群処理用モデルに入力します. 説明では点群の各点の特徴量として擬似ラベルのみを使用しましたが, 擬似ラベルの代わりにRGB画像のRGB値を使用することや, RGB値と擬似ラベルの両方を同時に使用することもできます.
最後に, 前処理によって特徴量を増やした点群 (前処理済み点群) に対して既存の点群処理手法を適用します. 実験では, RGB値や擬似ラベルなどを点群の新たな特徴量として活用した場合やそうでない場合の推論結果を比較することで, その有効性を検証します. 具体的には, 車の位置を推定する物体検出タスクや, どこにどんな物体があるかを識別してから各点を物体の種類 (クラス) 毎に色塗りするセマンティックセグメンテーションタスクにおいて, RGB画像から得られる特徴量を活用することで好ましい結果が得られるかを検証しました.

実験
データセット
今回の検証実験では, KITTI [4]とSemanticKITTI [9], The Cityscapes Dataset [10]という3つのOpen Datasetを使用しました.
KITTI [4]は自動運転の研究・開発に使用されるデータセットの中で最も人気のあるものの一つです. さまざまなシチュエーションを車載センサーで撮影したデータで構成されており, さらには, 3次元の点群だけでなく, 対応するRGB画像や深度画像など様々な種類のデータで構成されています (図1). そのため, 点群上での3次元物体検出だけでなく, 他の車両や歩行者との距離をRGB画像から推定する深度推定など, 多くの分野 (タスク) の研究に使用可能です. 実験をシンプルにするために, 今回は点群中の車両の位置を推定する3次元物体検出にタスクを絞ります. 実験では, 点群だけでなく7,481枚の学習画像と7,518枚のテスト画像を使用します.
SemanticKITTI [9]は点群のセマンティックセグメンテーションのための大規模なOutdoor-Scene Datasetです. このデータセットは前述のKITTI [4]から派生したもので, 車載LiDARの360°全視野に対して, 点単位でより高密度のアノテーション (クラスラベル) を付与して拡張しています (図6). そのため, 車両や歩行者の位置などをより正確に推定する研究に使用されています. このデータセットでは, 訓練データとして23,201点, テストデータとして20,351点の点群および対応するRGB画像が提供されています. 点群中の各点は28の意味カテゴリ (いわゆるクラスラベル) のうちの1つでアノテーションされています. 意味カテゴリの内訳は図7の通りです.


The Cityscapes Dataset [10]は, 50都市の風景を撮影して得られた多種多様なRGB画像からなる大規模データセットです (図8) . このデータセットでは, 背景を含めて20クラスのクラスラベルがピクセルレベルで割り当てられており, 都市の風景写真のセマンティックセグメンテーションの研究にしばしば用いられています. 今回の実験では, このデータセットを用いて学習した画像認識用モデルを用いて, RGB画像の擬似的なアノテーション情報 (擬似ラベル) を生成します.

物体検出タスクにおける有効性の検証
まず, 物体検出タスクにおいて, 点群のスパースな情報を補う特徴量としてRGB値と画像のアノテーション情報が有効であることを検証します. 画像のアノテーション情報は, The Cityscapes Datasetで事前学習した画像認識ネットワーク (DeepLabv3 [11]) を用いて各RGB画像のセマンティックセグメンテーションを行うことで, 擬似的なアノテーション情報 (擬似ラベル) を生成しました. 実験では, さまざまな特徴量を入力して訓練したネットワークの学習結果を比較します. 今回は, 4種類の組み合わせを行います. それぞれの組み合わせは, 特徴量がXYZ座標のみ (pcd), XYZ座標及び対応するRGB値のみ (pcd+rgb), XYZ座標及び対応する擬似ラベルのみ (pcd+label), XYZ座標と擬似ラベル, RGB値 (pcd+label+rgb) です. 実験で使用するネットワークはPointPillars [12]という3次元物体検出のためのDeep Neural Networkです. 4種類の組み合わせの特徴量を入力してネットワークを学習させ, その後にテストデータを推論させた結果を図9, 10に示しました.
テストデータに対する損失の値の推移を可視化した図9から, 特徴量を追加することでネットワークの認識性能が向上することがわかりました. 特に, 擬似ラベルとRGB値の両方を特徴量にしたpcd+label+rgbは, 学習の途中でどの組み合わせよりも低い損失の値を示しただけでなく, 学習の収束が最も早いという結果になりました. また, 実際にテストデータの物体検出 (車両の検出) を行った図10からも, 特徴量を追加することでネットワークの認識性能が向上することがわかりました. この図では, pcd, pcd+label+rgb, ground truthから得られるBounding Box (bbox) を, それぞれ緑枠, 黒枠, 赤枠で表示しています. 赤枠 (Ground Truth) に最も近いbboxが黒枠であることから, 定性評価でもpcd+label+rgbが最も良い結果となりました.
これらのことから, RGB値と擬似ラベルを用いて点群のスパースな情報を補うことでネットワークの物体検出性能が向上するだけでなく, 学習の収束速度改善にも効果があることがわかりました.


セマンティックセグメンテーションタスクにおける有効性の検証
次に, セマンティックセグメンテーションタスクにおいてもRGB値と画像のアノテーション情報が特徴量として有効であることを検証します. 擬似ラベルの生成方法や特徴量の組み合わせパターンは前節と同様です. 実験で使用するネットワークはKPConv [13]という3次元セマンティックセグメンテーションのためのDeep Neural Networkです. 4種類の組み合わせの特徴量を入力してネットワークを学習させ, その後にテストデータを推論させた結果を図11, 12に示しました.
テストデータに対する認識性能 (Intersection over Union, IoU) の推移を可視化した図11から, セマンティックセグメンテーションタスクでもRGB値と擬似ラベルの両方を特徴量にすることでネットワークの認識性能が向上することがわかりました. また, 擬似ラベルとRGB値の両方を特徴量にしたpcd+label+rgbが最も高い認識性能 (IoU) を示す一方で, ベースラインであるpcdに特徴量を追加したpcd+rgbとpcd+labelのIoUの値はベースラインを下回るという結果が得られました. これは, 点群上での複雑なタスクを行う場合, RGB値や擬似ラベルは精度に悪影響を与えるリスクがあるのに対し, RGB値と擬似ラベルの両方を同時に特徴量として使用するとその悪影響を減らし, 精度向上に寄与する効果があることを示唆しています.
さらに, セマンティックセグメンテーションの結果を可視化した図12でも同様の結果が得られました. 図12中の黄丸部分は, データセット中の正解データ (Ground Truth, GT) では車両のラベルが割り当てられていますが, RGB画像で確認すると植物に見えます. 学習済みネットワークの推論結果では, pcdは植物を車両 (赤色) だと認識しているのに対し, pcd+label+rgbは車両ではない (青色) と認識しています. これは, 擬似ラベルとRGB値の両方を同時に特徴量として使用することの有効性を示唆しています.
これらのことから, 擬似ラベルとRGB値を用いて点群のスパースな情報を補うことで, ネットワークの物体認識精度を向上させられることがわかりました.


まとめ
本記事では, CVPR2020で採択されたPointPainting [6]の追試を通して, 画像から得られる特徴量を活用することは点群上での物体認識性能を高められることを確認しました. 特に, 今回の検証実験では次の2つのことを確認できました. まず, RGB値と擬似ラベルの両方を同時に特徴量として使用することで, 認識性能を向上させる効果があることが確認できました. 次に, 特徴量として使用するのがRGB値と擬似ラベルのどちらかである場合, タスクによっては逆効果となる可能性があるということも確認できました. これらのことから, 3次元物体認識で2次元の画像を活用することは有効であるものの, 活用方法には注意が必要なようです. 今回行った実験はかなりシンプルでしたが, 論文ではより大規模な実験が行なわれているので, 点群と画像の活用にご興味がある方はぜひご一読することをお勧めします.
さいごに
Ridge-iでは様々なポジションで積極採用中です. カジュアル面談も可能ですので, ご興味がある方は是非ご連絡ください.
参考文献
[1] Geiger, A., Lenz, P., Stiller, C., & Urtasun, R. (2013). Vision meets robotics: The kitti dataset. The International Journal of Robotics Research, 32(11), 1231-1237.
[2] Cornelis, N., Leibe, B., Cornelis, K., & Van Gool, L. (2008). 3d urban scene modeling integrating recognition and reconstruction. International Journal of Computer Vision, 78(2), 121-141.
[3] Austin, M., Delgoshaei, P., Coelho, M., & Heidarinejad, M. (2020). Architecting smart city digital twins: Combined semantic model and machine learning approach. Journal of Management in Engineering, 36(4), 04020026.
[4] Geiger, A., Lenz, P., & Urtasun, R. (2012, June). Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE conference on computer vision and pattern recognition (pp. 3354-3361). IEEE.
[5] Su, H., Jampani, V., Sun, D., Maji, S., Kalogerakis, E., Yang, M. H., & Kautz, J. (2018). Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2530-2539).
[6] Vora, S., Lang, A. H., Helou, B., & Beijbom, O. (2020). Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4604-4612).
[7] Qi, C. R., Liu, W., Wu, C., Su, H., & Guibas, L. J. (2018). Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 918-927).
[8] Xu, D., Anguelov, D., & Jain, A. (2018). Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 244-253).
[9] Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke, S., Stachniss, C., & Gall, J. (2019). Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9297-9307).
[10] Cordts, M., Omran, M., Ramos, S., Scharwächter, T., Enzweiler, M., Benenson, R., ... & Schiele, B. (2015, June). The cityscapes dataset. In CVPR Workshop on the Future of Datasets in Vision (Vol. 2). sn.
[11] Chen, L. C., Zhu, Y., Papandreou, G., Schroff, F., & Adam, H. (2018). Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV) (pp. 801-818).
[12] Lang, A. H., Vora, S., Caesar, H., Zhou, L., Yang, J., & Beijbom, O. (2019). Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12697-12705).
[13] Thomas, H., Qi, C. R., Deschaud, J. E., Marcotegui, B., Goulette, F., & Guibas, L. J. (2019). Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6411-6420).