はじめに
AIとの関連性が高いタスクの1つに音声認識があります。 音声認識は音声が入力されたときに話されている内容をテキストとして書き起こすタスクです。 AIサービスで音声データを活用する際に、前処理としての利用が期待されます。
本稿は音声関連のAI技術に興味を持っていただくことを目的に、代表的なタスクである音声認識を取り上げ、 ニューラルネットワークを利用した音声認識の基本的な方法・代表的な大規模学習済みモデルを紹介させていただきます。
音声認識の基本的な仕組み
ニューラルネットワークや深層学習を利用した音声認識手法は大きく2つに分けられます。
- Connectionist Temporal Classification(CTC)損失[1]ベースの手法
- Attentionベース[2]の手法
以下ではそれぞれについての基本的な事項をまとめます。
CTC損失ベースの手法
音声認識ではモデルの入力の音声特徴量とターゲットとなるテキストの長さが異なります。 そこで利用されるのがCTC損失関数[1]です。CTCは系列長の異なる出力とラベルを対応づける損失関数です。
CTC損失関数の基本的なアイディアはモデルの出力に新しいターゲットクラスNullを追加することです。
Nullクラスは何も出力しないクラスとして扱われます。
例えばモデルの出力が時系列で(h, _, e, _, _, l, _, l, o, _ )と出力された場合は、(h, e, l, l, o)と変換します
(ただし_はNullクラスの出力とする)。また、Nullを挟まずに同じ出力が並んだ場合も1文字として扱います
(これは伝統的な音声認識に用いられる隠れマルコフモデル(Hidden Markov Model:HMM)に基づいて、状態が変化していないと考えることができるためです)。
例えば(h, h, _ e, _, l _, l, o)のhはNullを挟まないため1文字のhに変換します。
CTCは変換後のテキストがターゲットのテキストと一致する確率を計算し、その負の対数確率を最小化する損失関数です。
具体的な確率はモデル出力系列$\bar{Y}$に対して、変換後の列$Y$に変換する関数を$\beta$とすると、
$$
{\rm P}(Y|X) = \sum_{\bar{Y} \in \beta^{-1}(Y)} {\rm P}(\bar{Y}|X)
$$
で計算されます。$X$は入力特徴で音声認識では音声そのものが利用されたり、周波数分析された特徴が利用されたりします。
例えば出力が(h, _, e, _, _, l, _, l, o, _ )の場合も(h, e, l, _, _, _, _, l, o, _ )の場合も
変換後の結果は同じになります。このような正解テキストとなる複数のパターンの確率を計算し、最大化する損失がCTCです。
変換後の結果$Y$に至る複数の$\bar{Y}$の確率計算のために動的計画法をベースとしたForwardアルゴリズムと呼ばれる方法が利用されます。
RNN Transducer (RNN-t)
CTCの拡張としてRNN-t[3][4]があります。 CTCはモデル出力間の依存関係を考慮できませんが、RNN-tでは過去の出力系列を考慮することができます。 CTCベースのモデルはタイムステップ$t$の出力確率${\rm P}(y_t|X)$が入力特徴$X$のみに依存するのに対し、RNN-tでは$ {\rm P}(y_t|X,Y_t)$ と、$X$の他に過去のモデル出力にも依存します。ただし、$Y_{t}$はタイムステップ$t-1$までのテキスト出力とします。
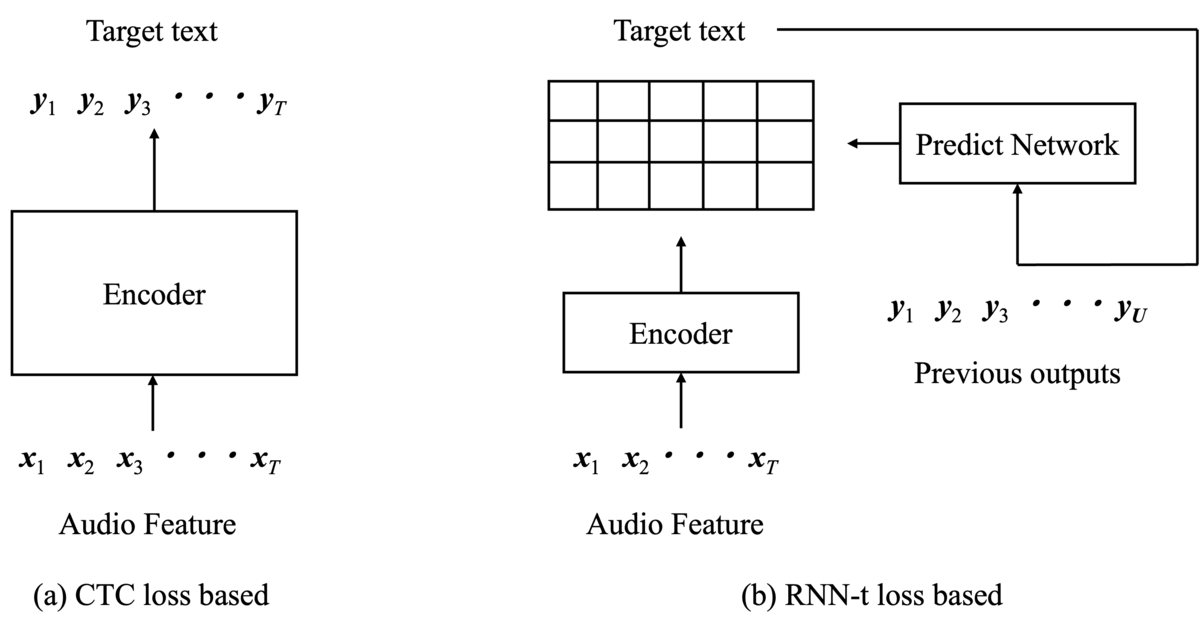
図1は具体的なモデルの構造の比較です。図1(a)のCTCベースのモデルは エンコーダの出力のみを利用しています。対して、図1(b)のRNN-tはエンコーダの他に予測ネットワーク(Predict network)と呼ばれるモデルが存在します。 予測ネットワークは過去のモデル出力を入力とします。 図1(b)のようにエンコーダと予測ネットワークの出力を組み合わせて格子状の出力が生成されます。 CTCのモデル出力は特徴時系列長$T$、ターゲット数$N$の時、$T \times N$の2次テンソルになるのに対し、 RNN-tは出力テキスト長$U$を含む$T \times U \times N$の3次元テンソルになります。 RNN-tはその格子状の中からCTC同様にターゲットテキストに変換できる複数パターンの確率を計算し、最大化します。
Attentionベースの手法
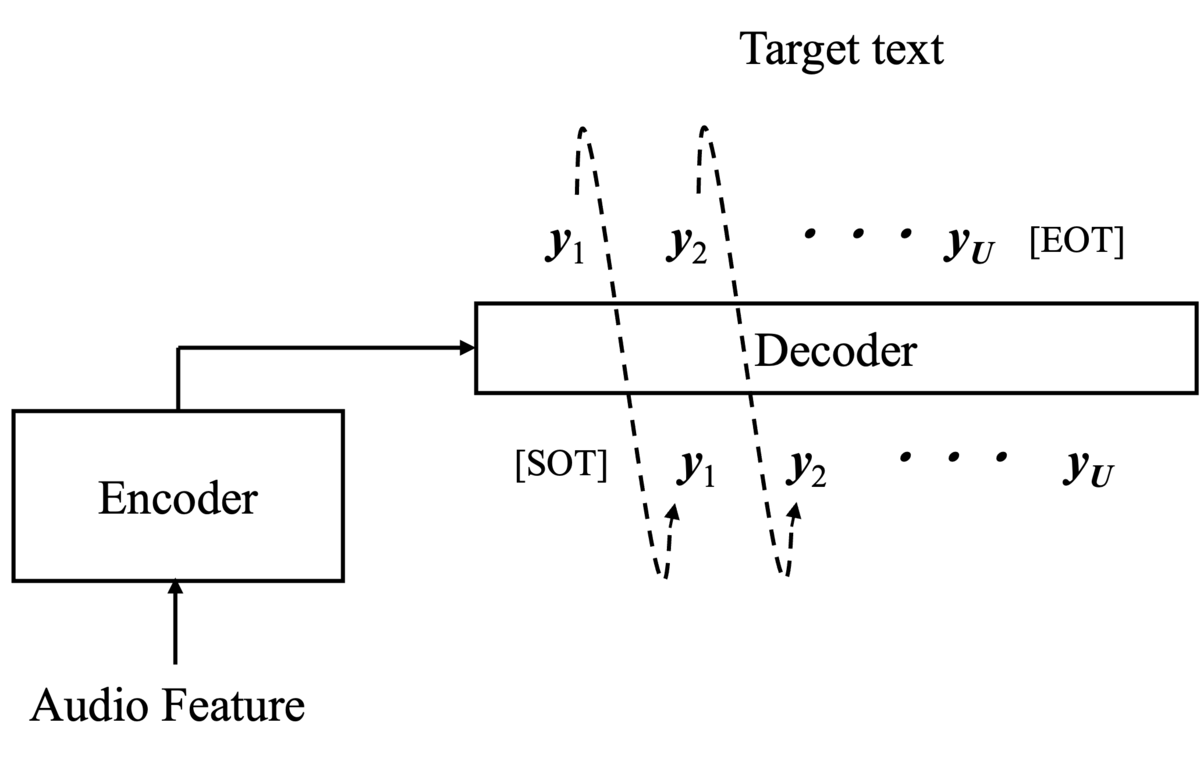
Attentionベースの手法[2]はCTCとは異なり、モデルの出力長自体が入力長に対して可変となります。 モデルはエンコーダとデコーダからなり、 デコーダはエンコーダの出力とデコーダ自身の過去の出力を利用して次の出力を予測します(図2)。 図2中の[SOT]と[EOT]はそれぞれ推論スタート時と終了時に対応するクラスです。 デコーダは終了に対応するクラス(図2中[EOT])が選ばれるまで繰り返し推論を続けます。 そのため、エンコーダへの入力長とは関係なく出力が可変長で生成できます。 学習はデコーダ出力とターゲットテキストとのクロスエントロピー損失で行います。
近年ではTransformer[5]のCross Attentionの構造をベースとしたAttentionベースの音声認識システムも多く出てきています。
音声に関する大規模学習済みモデル
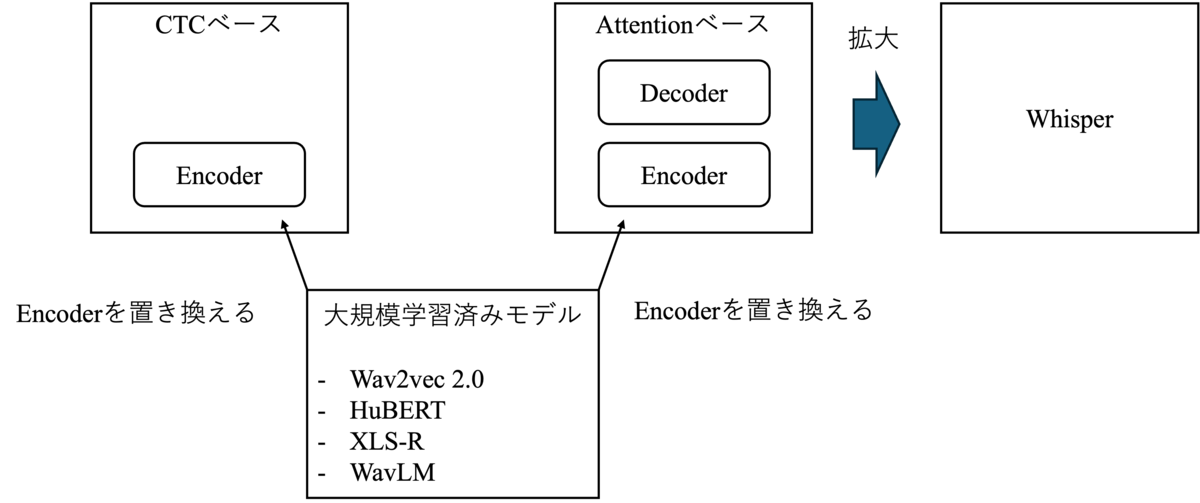
近年、CTCやAttentionベースの音声認識のエンコーダに大規模な教師なし表現学習モデルが利用される例が多くあります(図3)。 この章では、音声認識で利用される代表的な大規模学習済みモデルを紹介させていただきます。
音声の大規模学習済モデルとしてよく利用される代表的な構造は音響モデルと文脈モデルが合体した構造です(図4)。 代表的なモデルとしては、
- Wav2vec 2.0[6]
- HuBERT[7]
- XLS-R[8]
- WavLM[9]
があります。 CTCやAttentionベースの手法は、音声とそれに対応するテキストのペアを利用してモデルを学習する必要がありました。 一方、上記4つのモデルは大量の音声のみのデータを利用して事前学習をします。 これらの事前学習済みモデルをCTCやAttentionベースの手法のエンコーダとして利用し(図3参照)、 少量のペアデータでFine-tuningすることで高い音声認識の精度が出ることが報告されています。

学習は、
- 音声特徴をエンコーダ(CNNベース)によって潜在特徴に変換
- 潜在特徴の一部をマスク(図4の[M]部分)
- 言語モデルでマスクした部分の特徴を推定
- 推定された特徴と実際のターゲットの比較
によって行われます。 このモデル構造は、エンコーダによって音韻的な特徴(どんな音声か)を捉え、言語モデルによって文脈を捉えることが期待されています。
これらの手法の言語モデルで推定するターゲットは離散化されたクラスです。その離散化方法はそれぞれのモデルによって異なります。 以下で、それぞれのモデルの差分を紹介させていただきます。
また、上記4つとは構成は大きく異なりますが、大規模音声データにて事前学習されたモデルの代表の1つとして 教師なしの事前学習の問題点を提起しているWhisper[10]も最後に紹介させていただきます。
Wav2vec 2.0
Wav2vec 2.0[6]は上記の構造を取り入れた初めてのモデルです。
Wav2vec 2.0はエンコーダの出力である潜在特徴量をベースに、コードブックを用いた離散表現を取得します。 コードブックは離散表現を獲得するための特徴の辞書であり、その中に定義された各エントリと潜在特徴量との類似度を計算します。 その類似度に基づいてGumbel softmax[11]を適用することで、コードブックのインデックスを選択します。 Gumbel softmax は、確率的なサンプリングを行うため、類似度が最も高いクラスを選択しやすい一方で、 一定の確率で最大でないクラスを選択する特徴があります(Gumbel max trick に基づいた手法であり、強化学習などにも用いられます)。 事前学習時には、マスクされた部分の推定特徴量と、コードブックから選択された特徴量の間でContrastive損失を計算します。
Wav2vec 2.0は大量の音声のみのデータを利用して事前学習(表現学習)した上で、出力層を追加し、音声とテキストのペアを利用してFine tuningします (論文内ではCTCベースの手法を採用)。 Librispeech[12]という英語音声データのベンチマーク評価で良い性能でした (10時間分の発話とテキストのペアデータでFine tuningした場合の単語誤り率が4.0%、 これは100個の単語があったときに4単語分の間違った認識結果が含まれることに相当します)。 Librispeech公開時の実験では学習時に発話時間が約1000時間のペアデータを利用して学習していたため(当時のモデルでは単語誤り率で13.97%)、 それと比較しても大幅にペアデータが少ない条件でモデルの構築ができたことがわかります。
HuBERT
HuBERT[7]は離散クラスのターゲット生成方法を見直すことでWav2vec2.0の学習を安定化させ、性能向上に寄与したモデルです。
wav2vecはEncoderの出力を利用してオンラインでターゲットクラスを決定していました。 HuBERTは各Epoch開始時点でモデルの潜在特徴量をクラスタリングすることでターゲットを定めます。 ただし、学習開始時(1Epoch目)のみ音響特徴量を直接クラスタリングします。 クラスタリングはシンプルなk-Means, GMMが利用されています(実験ではk-Meansを利用)。 HuBERTはWav2vec 2.0とは違い、クラスタリングされたクラスに対するクロスエントロピーで事前学習されます。
英語の音声データ(Librispeech)により評価され、10時間分のペアデータでのFine tuningで単語誤り率 3.5%を達成しました。
XLS-R
XLS-R[8]は複数言語に拡張されたモデルです。
XLS-Rの事前学習の方法はWav2vec 2.0をベースとしています。 Wav2vec 2.0との大きな差分として、より多様なデータセットを利用して事前学習されています。 具体的には、128言語をカバーするデータセットを利用して事前学習されています。
評価においても複数言語のデータセットを利用して評価が行われ、従来の複数言語の音声認識モデルと同等の高い性能を達成しています (例えば8言語の音声認識実験の1つでは最大10.9%の単語誤り率を達成しています)。
その他にも音声翻訳や話者認識実験も行われています。
WavLM
上記3つのモデルは主に音声認識に焦点をおいた事前学習モデルでした。 WavLM[9]はより多様な音声タスクに対応可能な高性能な音声表現を獲得しました。
基本的な事前学習の方法は、HuBERTと同じです。ただし、モデルに音声を入力する際にノイズを挿入します。 ターゲットの生成時はノイズ挿入前のクリーンな音声に対してクラスタリングを適応します。 これにより何をしゃべっているかという音韻的な特徴だけでなくノイズが含まれる音声から ターゲットとなる発話者の発話特性(話者性など)も獲得されることが期待されます。
WavLMは音声の表現学習に関する複数タスクを評価するためのSuperB[13]ベンチマークで評価され、 全てのタスクでWav2vec 2.0を上回り、多くのタスクで当時のベンチマーク内での最高の性能を達成しました (例えばSuperBの音声認識実験では単語誤り率3.44%を達成)。
Whisper
Whisper[10]は大規模な多言語教師ありデータを活用して多言語対応と雑音耐性に優れた音声認識モデルです。 Attentionベースのモデルを大幅に拡大したモデルと捉えることができます。
Whisperモデルも学習済モデルとして多くの論文で利用されています。 上記に挙げたモデルの構造とは大きく異なります。 モデル構造はシンプルなTransformerの構造をベースとしています。 また、他の手法と異なり多くの音声とテキストのペアをインターネットなどから準備をして、学習に利用しました。 Whisperはデコーダの入力にタスクの指示となる特別な入力を加えることで、複数言語の音声認識や翻訳など、さまざまなタスクに対応することが可能です。
Whisperの論文では、Wav2vec 2.0などの教師なし表現学習が特定のコンテンツへの偏ってしまう点を指摘しています。 実験では、Wav2vec 2.0と比較したとき、Librispeechでの評価では同程度の性能が出ているものの、 そのほかのデータではWhisperの性能が大きく上回ったことを報告しています。
まとめ
今回は、音声認識の基本技術といくつかの代表的な大規模学習済モデルを紹介いたしました。
Wav2vec 2.0が大きなインパクトを残し、それを中心に複数言語・複数タスクなどに対応できるモデルも登場してきています (本稿にはありませんが、画像・音声・テキストすべてに適応できるモデルも提案されています)。 本文内でも少し触れさせていただいたとおり、事前学習モデルは音声認識に限らず、Fine tuningにより さまざまなタスクへの応用が可能となり研究の中心的な要素の1つとなっています。
次回のブログ記事にて、近年の音声認識の技術的な課題を国際会議の論文をベースに紹介する予定にしています。
参考文献
[1] A. Graves et al., "Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks," In Proceedings of the International Conference on Machine Learning (ICML), pp. 369-376, 2006.
[2] J. Chorowski et al., "Attention-Based Models for Speech Recognition," Advances in Neural Information Processing Systems, 2014.
[3] A. Graves et al., "Sequence Transduction with Recurrent Neural Networks, " arXiv preprint, arXiv:1211.3711, 2012, https://arxiv.org/abs/1211.3711.
[4] Y. He et al., "Streaming End-to-end Speech Recognition for Mobile Devices, " In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019.
[5] A. Vaswani et al., "Attention is All you Need," Advances in Neural Information Processing Systems (NeurIPS), 2017.
[6] A. Baevski et al., "wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations," Advances in Neural Information Processing Systems (NeurIPS), 2020.
[7] W. Hsu et al., "HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units," IEEE/ACM Transactions on Audio, Speech, and Language Processing, pp. 3451 - 3460, 2021.
[8] A. Babu et al., "XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale," arXiv preprint, arXiv:2111.09296, 2021, https://arxiv.org/abs/2111.09296.
[9] S. Chen et al., "WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing," IEEE Journal of Selected Topics in Signal Processing, pp. 1505 - 1518, 2022.
[10] A. Radford et al., "Robust Speech Recognition via Large-Scale Weak Supervision," In Proceedings of the International Conference on Machine Learning (ICML), 2023.
[11] E. Jang et al., "Categorical Reparametrization with Gumbel-Softmax," Proceedings of the International Conference on Learning Representations (ICLR), 2017.
[12] V.Panayotov et al., "Librispeech: An ASR Corpus based on Public Domain Audiobooks," In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015.
[13] S. Yang et al., "SUPERB: Speech processing Universal PERformance Benchmark," In Proceedings of the INTERSPEECH, pp. 1194-1198, 2021.