こんにちは,株式会社Ridge-iの竹本です.本記事では画像を用いた教師なし異常検知タスクとその手法を紹介します.
TL;DR
- 教師なし異常検知のタスク概要を紹介
- 教師なし異常検知の手法を紹介
- 異常検知手法を試せるライブラリを紹介
教師なし異常検知タスクとは
正常データのみを使って,想定とは異なるパターンを持つデータを検出するタスクです.画像を用いた教師なし異常検知タスクの代表的な活用例として製造業での異常製品の検出が挙げられます.製造分野において検品は品質保証の面で重要な工程であり,人間がそれを行う上で発生するヒューマンエラー,検査の属人化,人件費を避けるために近年機械に代替させる傾向が高まっています. このタスクに求められる性質には,以下の3つがあります.
- 正常画像のみでの学習
- 未知の異常ケースに対する高い汎化性能
- リアルタイムで処理可能な実行速度
一般的に異常の範囲は広く,小さい擦り傷から部品の欠落のような大きな欠陥まで多岐に渡ります.そのため異常データの収集は困難であり,基本的に問題設定は教師なし学習になります.また製造業に適用する際は,限られた時間で大量の製品を検品するため,速い推論速度が必要となります.
データセット
MVTec ADデータセットは教師なし異常検知を扱う論文で最もよく使用されるベンチマークデータセットです.2019年に発表されたこちらのデータセットは製造現場での異常検出を想定し,オブジェクトにはボトル,錠剤,歯ブラシ,ナットなど15種類が用意されて,全ての画像にピクセルレベルの異常箇所のアノテーションがセットになっています.

手法の紹介
近年,教師なし異常検知タスクでは事前に学習済みの特徴量抽出器で得た特徴量から,k-Nearest Neighborなどを用いて異常を検出する手法が多く開発されています.その中で代表的な手法をピックアップして紹介します.
Deep Nearest Neighbor Anomaly Detection
Deep Nearest Neighbor Anomaly Detectionは特徴量抽出器である事前学習済みのモデルと異常検知として長く用いられているkNNを組み合わせた手法です.
学習時にはImageNetデータセットで学習済みのResNetを用いて,正常な画像から抽出した特徴量 を保存しておき,推論時にはテスト画像の特徴量
とのkNN距離を算出しそれを異常スコアとして正常/異常を判定します.この時,特徴量抽出器の再学習が不要な点がこの手法の特徴です.kNN距離は以下で求められます.
式中の は学習用データの特徴量(
)の中からユークリッド距離(他の距離尺度でも可能)でテスト画像
と最も近い
個を示していて,算出された
が閾値を超えているかで画像
が異常かどうかを判定しています.この手法が以降の手法の土台になっています.
SPADE: Semantic Pyramid Anomaly Detection
これまでkNNベースの手法には「画像」単位でしか異常の判定ができないという大きな欠点でありました.このSPADEは「画像」単位だけでなく,「ピクセル」単位での異常判定も可能にしたkNNベースの手法です.異常箇所の特定はモデル出力の説明可能性を向上させ,現場の作業者に対してより高いサポートが可能になります. 画像単位の異常判定方法は,上記のDeep Nearest Neighbor Anomaly Detectionと同じアルゴリズムを採用しています.一方ピクセル単位の異常検出については,テスト画像と検索した正常画像で位置を照らし合わせ,差分を見つけ出すというシンプルなアイデアが出発点となっています.しかしこの比較を行う上で幾つかの課題点がありました.
- 対象画像内に正常部分が複数存在する場合,特定の正常画像との比較が困難
- 小規模データセットや異常変化が複雑な画像の場合,それと類似する正常画像を見つけることが難しく,誤検出が発生する
- 画像の差分計算を行うことで,損失関数に対して非常に敏感になる可能性がある
上記を克服するために,SPADEでは以下を行います.
- 特徴量抽出器
を用いて,全ての正常な学習画像とテスト画像の全ピクセル
における特徴量を抽出(事前学習済みの特徴量抽出器は再学習不要.また,解像度と幅広いコンテキストの両方を得るために,特徴量を連結する)
個の最近傍の全ピクセルの特徴量のギャラリー
を構築
- 特徴量
とギャラリー
内の
最近傍との間での平均距離によってピクセル
の異常スコアを算出
最終的にテスト画像内のピクセル
の異常スコアは以下で求めることができます.
そして与えられた閾値 に対して,
である(
個の最近傍の正常画像の中で対応する近いピクセルが見つからない)場合,ピクセル
は異常と判定されます.
以下の画像は検証実験を行なった結果で左列から,異常画像,正常画像,出力された異常箇所のセグメーテーションマスク,入力画像との重ね合わせであり,ピクセル単位に正常/異常を判定しているのがわかります.

PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
PaDiMは,SPADEと同様に画像単位の異常検知と異常位置の検出を行いますが,最近傍探索は使わずにSPADEから以下2点を改善しています.
以下の図がPaDiMの概要です.
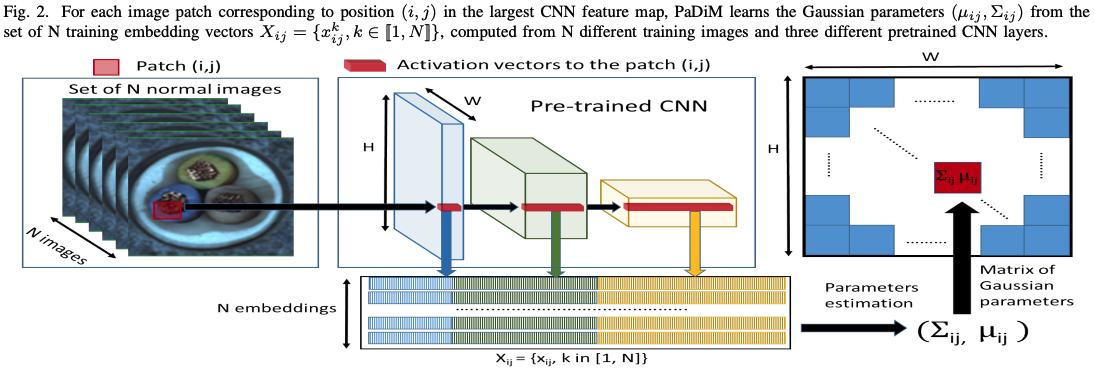
上記の改善のためにPaDiMが行なったことは以下です.
- パッチ毎の処理と複数層での特徴の使用:
入力画像の各パッチ毎(CNNの中で最大の特徴量マップのピクセルに対応)に特徴量抽出を行い,その際に事前学習済みの各層での特徴量を連結して細かな特徴と大域的な特徴の両方を含ませます. - 特徴量の統計値化:
上記で得られた特徴量から算出される平均と共分散を算出しそれらを推論時に使用します(抽出した特徴量は多変量ガウス分布によって生成されると仮定). - マハラノビス距離による異常スコアの算出: 推論時にはテスト画像のパッチ特徴量と学習で得た分布とのマハラノビス距離を用いて異常スコアを算出し,画像レベルの異常検知と異常箇所の検出を行います.これにより,大量の距離値を扱う必要がないためkNNベース手法のスケーラビリティの問題を解決しています.またその際に,高速化のために特徴量をサンプリングも行っています(論文内ではPCAよりランダムサンプリングの方が性能が良いと報告しています).
左から,正常画像,異常画像,PaDiMが出力したヒートマップです.ヒートマップは正常箇所を青,異常箇所を黄色で示しています.

PatchCore: Towards Total Recall in Industrial Anomaly Detection
PatchcoreはPaDiMとは異なり,最近傍探索を用いて以下3点の改善を行いました.
- テスト時に使える異常情報を最大化
- ImageNetクラスへのバイアスの低減
- 推論速度の高速化
以下の図がPatchCoreの概要です.
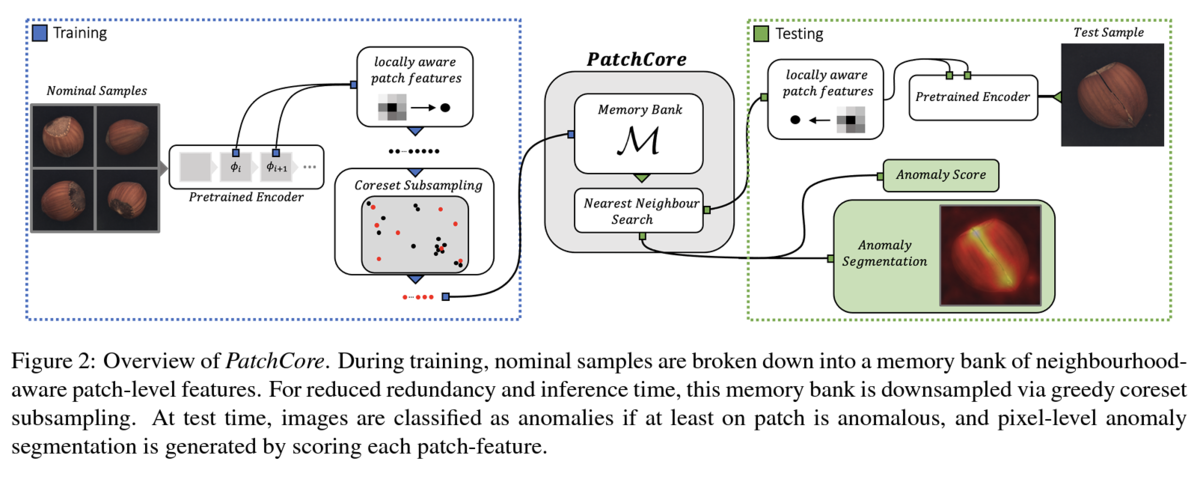
PatchCoreの手法は3つの要素で構成されています.
位置情報を持った特徴量の抽出
上述のDeep Nearest Neighbor Anomaly DetectionやSPADEはCNNの最終層の特徴をその後のkNNに使用していますが,それに対して2つの問題点を指摘しています.
- 最終層から得られる特徴量は局所的な異常情報が欠落し,その後の最近傍探索に悪影響を及ぼす.
- 最終層からの深い特徴量は特に,ImageNetに偏っていて製造業などの異常検知タスクのデータとは重なっていない.
また浅い層での特徴量は一般的に広範で一般的で不適.そこで上記問題点を解決するためにPatchCoreでは,浅い層と深い層を使わずに,中間層の特徴量を使用します.
推論高速化のためのパッチ特徴量メモリバンクの軽量化
正常画像の枚数が増加に伴いメモリバンクも大きくなって,推論速度の低下と必要なストレージサイズが増加する問題が発生します.SPADEでは計算量の制限から,最終層の特徴量のグローバル平均していましたが,その結果ImageNetへの偏りが発生していました.そこでPatchCoreでは,推論時間を短縮しながらも性能を維持できる部分集合の探索(コアセットサンプリング)を行って,一部の特徴量だけをメモリバンクへ保存し高速化を行なっています.ただしそれを求める際にNP困難があるため,[Labs et al., 2018]によって提案されてた反復的な貪欲法を使って近似をおこなっています.以下はコアセットサンプリング時の方法をランダムサンプリングと貪欲法の2種類で行い比較した結果です(a:マルチモーダル分布,b:一様分布からサンプリングした青点の二次元データを使用した実験).視覚的に貪欲法ではクラスタの見逃しがなく,空間的に良く近似が出来ています.

パッチコアを用いた最近傍探索
推論時は正常画像から得られたパッチ特徴量の部分集合が保存されているメモリバンクとテスト画像の特徴量を用いて画像・ピクセル単位の異常検知を行います.画像単位の異常検知については,メモリバンクとテスト画像の特徴量の最近傍の距離を求め,その最大値によって異常スコアが得られます.ピクセル単位については,PaDiMと同様のステップでセグメンテーションマップを算出します.
下図がPatchCoreの出力結果です.それぞれの画像の異常箇所をオレンジの境界で示しています.

異常検知の最新手法を試せるライブラリの紹介:anomalib
ここからは,本記事で紹介した手法を含めた様々な異常検知手法を気軽に試せるPytorch Lightningベースのライブラリanomalibを紹介します.
Anomalib is a deep learning library that aims to collect state-of-the-art anomaly detection algorithms for benchmarking on both public and private datasets.
anomalibでは,MVTec ADデータセットのような主流のベンチマークデータセットや個人で作成したカスタムデータセットを対象に様々なモデルで学習,推論,ロギング,可視化,ハイパラメータ最適化などが行えます.使用可能なモデル一覧はこちらです.
インストールはPyPi経由で以下のコマンドで可能です.
$ pip install anomalib
まとめ
本記事では,教師なし異常検知タスクの概要とそれに関する手法を紹介しました.このタスクは製造現場を中心に幅広く有用であり,今後更に社会実装が進んでいくと予想されます.教師なし異常検知タスクでは,本記事で紹介した手法の他にも生成モデルやNormalizing Flowを用いたモデルなど様々な手法が開発されていますので,ご興味のある方は是非そちらの方も合わせてご覧になってください.
さいごに
Ridge-iでは様々なポジションで積極採用中です. カジュアル面談も可能ですのでご興味がある方は是非ご連絡ください.
参考文献
- Bergmann, P., Fauser, M., Sattlegger, D., & Steger, C. (2019). MVTec AD--A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9592-9600).
- Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. IEEE transactions on information theory, 13(1), 21-27.
- Pang, G., Shen, C., Cao, L., & Hengel, A. V. D. (2021). Deep learning for anomaly detection: A review. ACM Computing Surveys (CSUR), 54(2), 1-38.
- Cohen, N., & Hoshen, Y. (2020). Sub-image anomaly detection with deep pyramid correspondences. arXiv preprint arXiv:2005.02357.
- Defard, T., Setkov, A., Loesch, A., & Audigier, R. (2021, January). Padim: a patch distribution modeling framework for anomaly detection and localization. In International Conference on Pattern Recognition (pp. 475-489). Springer, Cham.
- Roth, K., Pemula, L., Zepeda, J., Schölkopf, B., Brox, T., & Gehler, P. (2022). Towards total recall in industrial anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14318-14328).
- Sener, O., & Savarese, S. (2017). Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489.
- Akcay, S., Ameln, D., Vaidya, A., Lakshmanan, B., Ahuja, N., & Genc, U. (2022). Anomalib: A Deep Learning Library for Anomaly Detection. arXiv preprint arXiv:2202.08341.