- はじめに
- ScalarDB Clusterとは
- ScalarDB Coreライブラリとの違い
- ScalarDB Clusterを導入するメリットと活用シチュエーション
- 2つのアクセス方式
- 構築・デプロイ
- 終わりに
- 引用文献
- 参考記事
はじめに
前回のブログ記事では、ScalarDB公式で掲載しているクイックスタートで、ScalarDB Coreライブラリを利用したDBアクセスを試してみました。
本記事では、分散型データベース管理システムであるScalarDB ClusterをAWSのKubernetes(K8s)環境であるElastic Kubernetes Service(EKS)上に構築する手順を解説します。EKSを活用することで、スケーラブルかつ高可用性のデータベースシステムを運用可能となります。
ScalarDB Clusterとは
ScalarDB Clusterは、データを複数のサーバーに分散して保存しながら、一貫性を保つ仕組みを提供するデータベースソリューションです。データの整合性を確保しながら、システム全体の可用性を高め、必要に応じてスムーズにスケールアップやスケールダウンが可能です。
Kubernetesを基盤とすることで、クラウドやオンプレミスなどのさまざまな環境に簡単に導入でき、運用管理の効率化が図れます。
ScalarDB Coreライブラリとの違い
ScalarDB Coreライブラリは、アプリケーションの内部に組み込むことで、異なるデータベースに対してACIDトランザクションを実現する軽量なライブラリです。これにより、単一のアプリケーションレベルで一貫性のあるデータ処理が可能になります。
一方、ScalarDB ClusterはKubernetes上に構築された複数のノード(サーバー)が協力して動作する仕組みです。
各ノードには複数のコンテナが配置され、分散されたデータを並列処理しながら管理します。クラスタ内のノードが相互に通信し、負荷分散や自動フェイルオーバーを行うことで、障害耐性を高めつつシステム全体のパフォーマンスを最適化します。
これにより、より大規模なシステムやトラフィックの多い環境にも適用できる柔軟なデータ管理が可能となります。
ScalarDB Clusterを導入するメリットと活用シチュエーション
ScalarDB Clusterを導入することで、以下のようなメリットがあります。
- スケーラビリティの向上: ワークロードに応じてノード数を動的に増減できるため、急激なアクセス増加にも柔軟に対応できます。
- 高可用性の確保: ノード障害が発生しても、自動的にフェイルオーバーが実行され、サービスを継続できます。
- データの一貫性: 分散環境でもACIDトランザクションが保証され、データの整合性を維持できます。
- 運用の自動化: Kubernetesを活用することで、スケーリング、監視、リカバリなどの管理タスクを効率化できます。
特に、以下のようなシチュエーションでの活用が適しています。
2つのアクセス方式
ScalarDB ClusterをAWS上に構築する場合には、下記いずれかのアクセス方式(client mode)を選択して構築します。
Indirect Client Mode
EKSクラスターとは異なる環境にアプリケーションをデプロイし、ロードバランサーやサービス等を経由してScalarDB Clusterにアクセスする方式です。
以下のような構成となり、Kubernetesの内部ネットワーク構造を知らなくてもアクセスが可能です。
ただし、接続先のエンドポイントが単一となる点や、ロードバランサ等を経由することによるわずかな通信遅延など、可用性やパフォーマンスに関する考慮が必要となります。
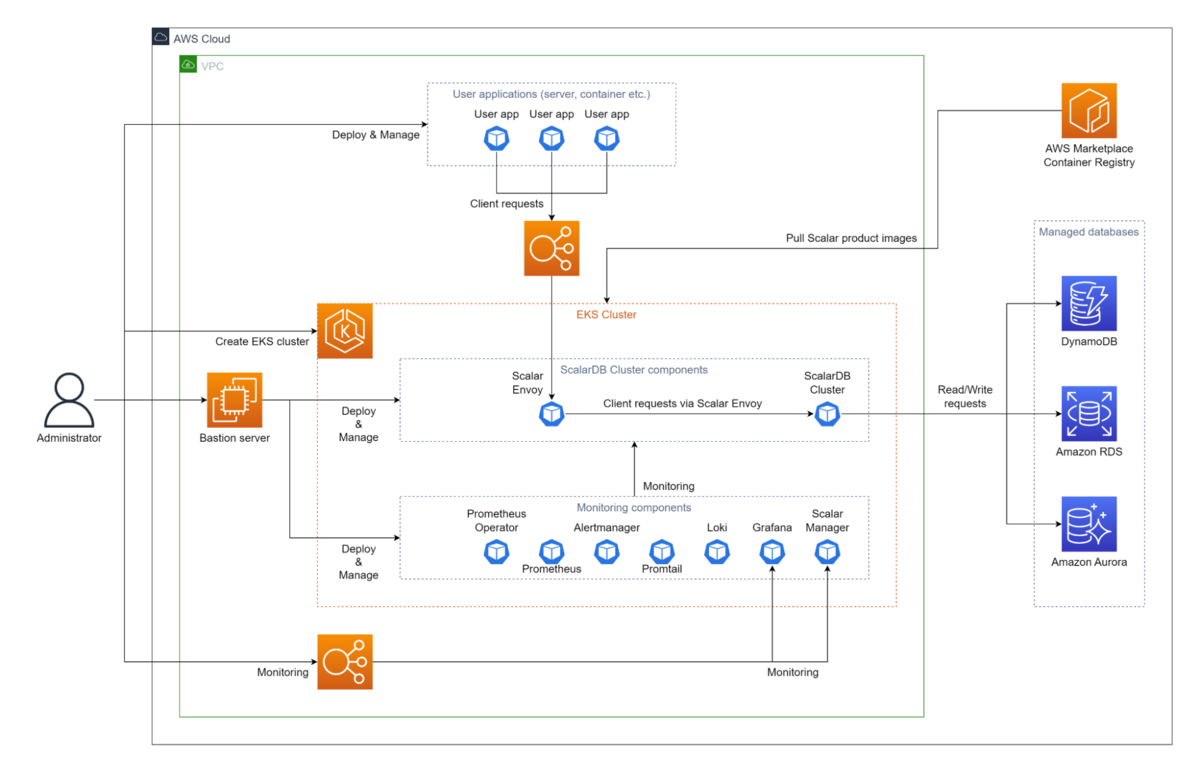 Indirect Client Mode構成イメージ ([1]より引用)
Indirect Client Mode構成イメージ ([1]より引用)
direct-kubernetes client mode
ScalarDB Clusterのデプロイメントと同じEKS クラスターにアプリケーションをデプロイし、アプリケーションからScalarDB Clusterに直接アクセスする方式です。
ネットワークの内部構造を理解して構築する必要がある一方で、アプリケーションから直接ScalarDB Clusterにアクセスすることによるパフォーマンスや可用性の向上が期待できます。
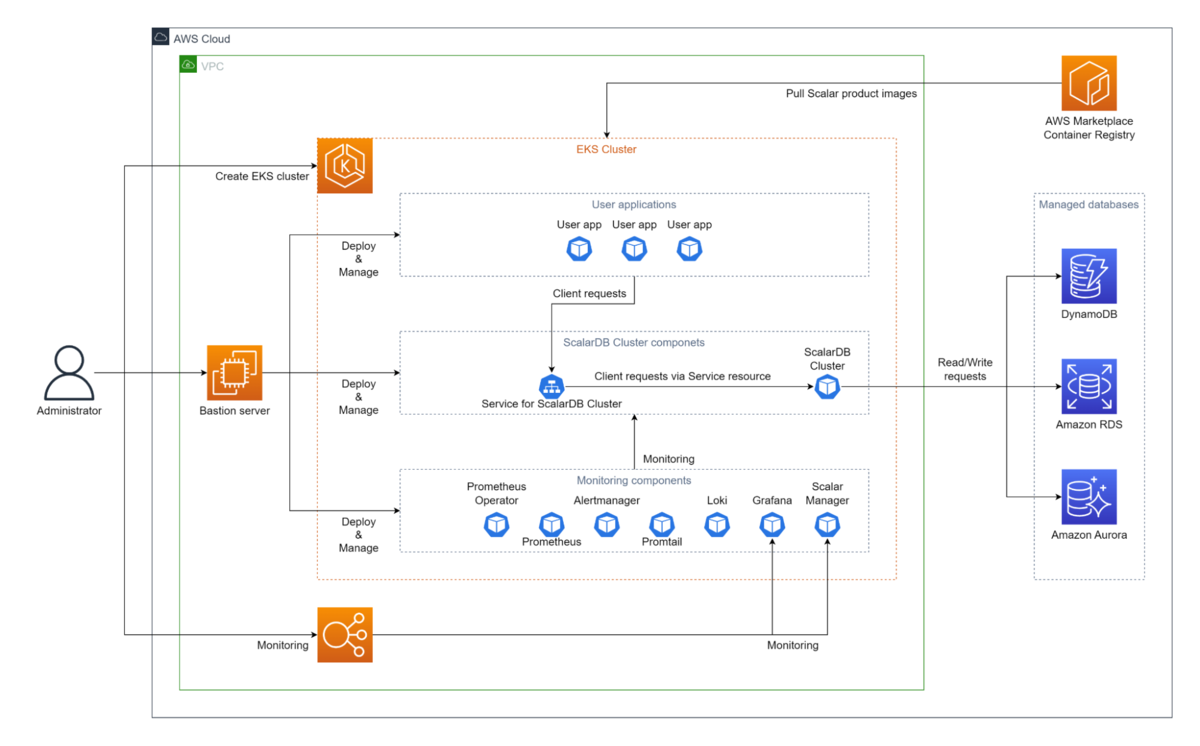 direct-kubernetes client mode構成イメージ ([1]より引用)
direct-kubernetes client mode構成イメージ ([1]より引用)
構築・デプロイ
では実際に、EKSを構築し、ScalarDB Clusterとアプリケーションをデプロイします。
今回デプロイするアプリケーションには、ScalarDB Clusterのクイックスタートで作成する電子商取引アプリケーションを利用します。
また、DBについてはDynamoDBとAmazon RDS (PostgreSQL)を利用し、分散データベースに対するアクセスを想定した形で構築を行っていきます。
1. 前提条件
今回は以下の前提条件で作業を進めていきます。
- 目的:製品検証(小規模構成)
- ライセンス:試用ライセンス
- アクセス方式:direct Kubernetes mode
- DBはDynamoDBとAmazon RDS (PostgreSQL)の2種類とし、以下の通り分散DBとして管理する。
- productsテーブル:DynamoDB
- customersテーブル:DynamoDB
- ordersテーブル:Amazon RDS (PostgreSQL)
- ノード構成:2~3台
- インスタンスタイプ:t3.medium
2. 作業環境セットアップ
2.1 AWS CLIのインストール・認証設定
AWS CLIは、AWSリソースをコマンドラインから操作するためのツールです。
これにより、AWSのインフラを簡単に管理できます。
OSに応じて以下のコマンドでインストールすることができます。
Mac (Homebrew)
brew install awscli
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
msiexec.exe /i https://awscli.amazonaws.com/AWSCLIV2.msi
AWS認証設定
インストールが完了したら、AWS アカウントの アクセスキー と シークレットアクセスキー を使用して、下記コマンドで認証設定を行います。
aws configure
各認証項目には以下の情報を設定します。
- AWS Access Key ID
- IAMで取得したキーを入力
- AWS Secret Access Key
- IAMで取得したキーを入力
- Default region name
- 利用するリージョンID(アジアパシフィック(東京)の場合はap-northeast-1)
- Default output format
設定確認
認証情報が正しく設定できていることを確認するために以下のコマンドを実行します。
aws sts get-caller-identity
以下のような結果が出力されれば完了です。
{ "UserId": "AROA...EXAMPLE", "Account": "123456789012", "Arn": "arn:aws:sts::123456789012:assumed-role/.../aws-cli" }
2.2 kubectl のインストール
kubectlは、Kubernetesクラスタを操作するためのコマンドラインツールです。
EKS上にて構築したKubernetesクラスタを操作するために利用します。
OSに応じて以下のコマンドでインストールすることができます。
Mac (Homebrew)
brew install kubectl
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" chmod +x kubectl sudo mv kubectl /usr/local/bin/
choco install kubernetes-cli
インストール確認
インストールが正しく設定できていることを確認するために以下のコマンドを実行します。
kubectl version --client
以下のような結果が出力されれば完了です。
Client Version: v1.20.0
2.3 eksctl のインストール
eksctlは、EKS クラスタの作成を簡単に行えるツールです。
これを使うことで、AWS上にKubernetes クラスタを迅速にセットアップできます。
OSに応じて以下のコマンドでインストールすることができます。
Mac (Homebrew)
brew tap weaveworks/tap brew install weaveworks/tap/eksctl
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp sudo mv /tmp/eksctl /usr/local/bin
choco install eksctl
インストール確認
インストールが正しく設定できていることを確認するために以下のコマンドを実行します。
eksctl version
以下のような結果が出力されれば完了です。
0.35.0
3. EKS クラスタのセットアップ
3.1 EKS クラスタの作成
以下のコマンドでEKS クラスタを作成します。
これにより、EKS 上に Kubernetes クラスターがセットアップされます。
eksctl create cluster --name scalardb-cluster \ --region ap-northeast-1 \ --nodegroup-name scalardb-nodes \ --node-type t3.medium \ --nodes 2 \ --nodes-min 1 \ --nodes-max 3 \ --managed
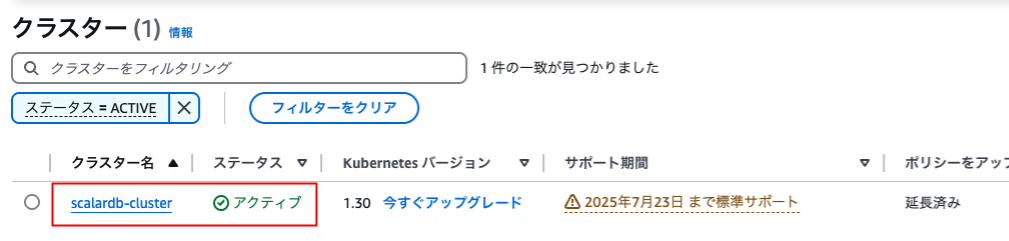
実行が完了したら、AWSの管理コンソールでAmazon Elastic Kubernetes Service(EKS)を表示し、以下の通り”scalardb-cluster”という名称のクラスタがステータス:アクティブで作成されていることを確認します。
3.2 kubectl の設定
EKS クラスタに接続するため、kubeconfigファイルを更新します。
aws eks update-kubeconfig --name scalardb-cluster --region ap-northeast-1
3.3 EKSクラスタの作成確認
kubeconfigファイルの更新が完了したら、以下のコマンドを実行してノードが取得できるか確認します。
kubectl get nodes
以下のようにノードが表示されれば、正しく作成・接続ができている状態です。
NAME STATUS ROLES AGE VERSION ip-192-168-30-90.ap-northeast-1.compute.internal Ready <none> 9d v1.30.9-eks-5d632ec ip-192-168-57-82.ap-northeast-1.compute.internal Ready <none> 9d v1.30.9-eks-5d632ec
4. DBのセットアップ
アプリケーションからアクセスするためのDBのセットアップを行います。
前提条件に記載の通り、今回はテーブルごとに以下のDBにアクセスすることを想定してセットアップします。
- productsテーブル:DynamoDB
- customersテーブル:DynamoDB
- ordersテーブル:Amazon RDS (PostgreSQL)
4.1 Amazon RDS (PostgreSQL)
Amazon RDSのPostgreSQLインスタンスを作成して接続確認を行います。
なお、ordersテーブルは後ほど実施するスキーマ定義のインポートにて行われるため、ここでの作成は不要です。
4.1.1 RDS インスタンス作成
※<sg-id>にはDBを構築するセキュリティグループのIDを設定します。
aws rds create-db-instance \ --db-instance-identifier scalardb-rds \ --db-instance-class db.t3.micro \ --engine postgres \ --allocated-storage 20 \ --master-username scalardb \ --master-user-password yourpassword \ --vpc-security-group-ids <sg-id>
4.1.2 RDS への接続確認
作成したRDSインスタンスへ接続できることを確認します。
<RDS-endpoint>には作成したRDSインスタンスのエンドポイントを設定します。
psql -h <rds-endpoint> -U scalardb -d postgres
4.2 DynamoDB
DynamoDBに productsテーブルとcustomersテーブルを作成します。
4.2.1 テーブル作成
下記のコマンドを実行してテーブルを作成します。
・productsテーブル
aws dynamodb create-table --table-name products \ --attribute-definitions AttributeName=product_id,AttributeType=S \ --key-schema AttributeName=product_id,KeyType=HASH \ --billing-mode PAY_PER_REQUEST
・customersテーブル
aws dynamodb create-table --table-name customers \ --attribute-definitions AttributeName=customer_id,AttributeType=S \ --key-schema AttributeName=customer_id,KeyType=HASH \ --billing-mode PAY_PER_REQUEST
4.2.2 テーブル確認
以下のコマンドを実行することで、DynamoDBにて作成されているテーブルを表示できます。
aws dynamodb list-tables
以下のようにテーブル名が表示されれば、テーブルが正しく作成されています。
{ "TableNames": [ "products", "customers" ] }
5. ScalarDB Clusterのデプロイ
ScalarDB ClusterをEKS上にデプロイしていきます。
5.1 Helmのセットアップ
HelmはKubernetes 用のパッケージマネージャーです。
Helmチャートを使用することでアプリケーションのデプロイ、管理、アップグレードが効率化できます。
以下のコマンドで、ScalarDBのパッケージの取得元リポジトリをセットアップします。
helm repo add scalardb https://scalar-labs.github.io/helm-charts helm repo update
以下のコマンドでリポジトリが正しく更新されているか確認します。
helm repo list
正しく更新されていれば、以下のようにリポジトリが出力されます。
NAME URL scalardb https://scalar-labs.github.io/helm-charts
5.2 名前空間の作成
以下のコマンドでKubernetesの名前空間を作成します。
kubectl create namespace scalardb
以下のコマンドで名前空間が正しく作成されているか確認します。
kubectl get namespaces
正しく作成されていれば、以下のように名前空間が出力されます。
NAME STATUS AGE default Active 3h56m scalardb Active 5m
5.3 values.yaml の作成
ScalarDB ClusterをEKS上にデプロイするために必要な設定を、values.yamlとして定義します。
このファイルには、アプリケーションが接続する DB情報や動作モード、使用するDocker イメージ、ライセンスキーなどを含めます。
<試用ライセンスキー>には、保持しているライセンスキー、<RDS-endpoint>には 4.1.2 RDS への接続確認 にて利用したRDSのエンドポイントを設定します。
また、multi_storage.tablesでテーブル毎に異なるアクセス先のDBを指定しております。
前提条件に記載の通り、テーブル毎のアクセス先は以下の通りとなります。
- productsテーブル:DynamoDB
- customersテーブル:DynamoDB
- ordersテーブル:Amazon RDS (PostgreSQL)
image: repository: ghcr.io/scalardb/scalardb-cluster-node-byol-premium tag: "3.14.1" imagePullSecrets: - name: ghcr-secret license: key: "<試用ライセンスキー>" cluster: mode: "direct" database: type: "multi-storage" multi_storage: storages: postgres: storage: "jdbc" jdbcUrl: "jdbc:postgresql://<RDS-endpoint>:5432/scalardb" username: "scalardb" password: "yourpassword" dynamodb: storage: "dynamo" endpoint_override: "https://dynamodb.ap-northeast-1.amazonaws.com" region: "ap-northeast-1" tables: orders: "postgres" products: "dynamodb" customers: "dynamodb"
各定義の内容は以下の通りです。 | key | 説明 | | :---- | :---- | | image.repository | ScalarDBのイメージを取得するリポジトリ | | image.tag | 取得するイメージのバージョン | | imagePullSecrets.name | イメージ取得に利用するsecretの名称(認証情報) | | license.key | ScalarDB のライセンスキーを指定 | | cluster.mode | 利用するアクセス方式 | | database.type | 使用するデータベースの種類 | | multi_storage.storages.postgres | PostgreSQLの接続情報 ※<RDS-endpoint>には 4.1.2 RDS への接続確認 にて利用したRDSのエンドポイントを設定 | | multi_storage.storages.dynamodb | DynamoDBの接続情報 | | multi_storage.tables | テーブルの接続先DBを指定 |
5.4 Helm でデプロイ
以下のコマンドでHelm チャートを使用して、ScalarDB ClusterをEKS上にデプロイします。
helm install scalardb-cluster scalardb/scalardb-cluster -f values.yaml
コマンドの内容は以下の通りです。
・helm instal
HelmチャートをKubernetes クラスタにインストールします。
ここでは、scalardb-clusterという名前でインストールしています。
・-f values.yaml
作成したvalues.yamlファイルを Helmチャートに適用し、デプロイ時に必要な設定を指定します。
・-n scalardb:
scalardb名前空間にデプロイを実行します。
上記実施後、下記コマンドでデプロイの確認を行います。
kubectl get pods -n scalardb
正しくデプロイできていれば、作成されたPodが以下のように表示されます。
NAME READY STATUS RESTARTS AGE scalardb-cluster-node-5765bbdd74-abcde 1/1 Running 0 10m
6. アプリケーションのデプロイ
6.1 デプロイするアプリケーション・ソースのクローン
ScalarDBを使用したサンプルアプリケーションのソースコードをGitHubからクローンします。
git clone https://github.com/scalar-labs/scalardb-samples cd scalardb-samples/scalardb-sample
6.2 database.properties を作成
アプリケーションにてDB接続をする際に利用するdatabase.propertiesファイルを作成します。
このファイルでは、ScalarDB Clusterの接続情報を指定します。
scalar.db.transaction_manager=cluster scalar.db.contact_points=<SCALARDB_CLUSTER_POD_IP>
ファイル内の設定内容は以下の通りです。
・scalar.db.transaction_manager
トランザクションマネージャの設定を行います。
cluster モードを指定することで、複数ノードによるクラスター接続が可能になります。
・scalar.db.contact_points
ScalarDB クラスターのノード IP を指定します。
ここには、実際の Kubernetes Cluster Podの IP を指定します。
IPアドレスは以下のコマンドの出力結果の”IP”の部分で確認します。
# 実行コマンド kubectl get pods -n scalardb -o wide # 出力結果 NAME READY STATUS RESTARTS AGE IP NODE scalardb-cluster-node-5765bbdd74-abcde 1/1 Running 0 10m 192.168.1.10 ip-xx-xx-xx-xx
6.3 スキーマの適用
ScalarDBのスキーマをロードするために、クローンしたソースに内包されているscalardb-cluster-schema-loaderを使用します。
これにより、データベースのスキーマが ScalarDB Clusterに適用されます。
<version>には、デプロイしたScalarDB Clusterに一致するバージョンを指定する必要があります。
(本blogの手順通りの場合は、values.yamlにて指定している”3.14.1”となります。)
java -jar scalardb-cluster-schema-loader-<version>-all.jar --config database.properties -f schema.json --coordinator
上記実行後、下記コマンドでordersテーブルが作成されていることを確認します。
<RDS-endpoint>には、 4.1.2 RDS への接続確認 にて利用したRDSのエンドポイントを設定します。
psql -h <rds-endpoint> -U scalardb -d postgres -c "SELECT * FROM orders;"
正しくスキーマが適用されていれば、以下のように空のテーブルが検索されます。
order_id | customer_id | product_id | quantity | price | status ----------+-------------+------------+----------+-------+-------- (0 rows)
6.4 Docker イメージのビルド
docker buildコマンドを利用して、ローカルのDockerイメージを作成します。
イメージ名はscalardb-sample-appとしています。
docker build -t scalardb-sample-app .
6.5 Amazon Elastic Container Registry (ECR)にプッシュ
Amazon ECRとは、Dockerコンテナイメージを保存するためのAWSのフルマネージド型サービスです。
これにより、コンテナイメージを簡単に管理・デプロイできます。
以下のコマンドを実行して、ローカルで作成したDockerイメージをECRにプッシュします。
<region>には利用するリージョンコード(本blogの手順通りであれば”ap-northeast-1”)、<account-id>には自身のAWSアカウントのIDを指定します。
aws ecr create-repository --repository-name scalardb-sample-app aws ecr get-login-password --region <region> | docker login --username AWS --password-stdin <account-id>.dkr.ecr.<region>.amazonaws.com docker tag scalardb-sample-app:latest <account-id>.dkr.ecr.<region>.amazonaws.com/scalardb-sample-app:latest docker push <account-id>.dkr.ecr.<region>.amazonaws.com/scalardb-sample-app:latest
6.6 Kubernetesにアプリケーションをデプロイ
6.6.1 deployment.yaml ファイルを作成
Kubernetesにアプリケーションをデプロイするための設定ファイルとして、deployment.yamlを作成します。
この設定で、アプリケーションはKubernetesのscalardb名前空間にデプロイされます。
<region>には利用するリージョンコード(本blogの手順通りであれば”ap-northeast-1”)、<account-id>には自身のAWSアカウントのIDを指定します。
apiVersion: apps/v1 kind: Deployment metadata: name: scalardb-sample-app namespace: scalardb spec: replicas: 1 selector: matchLabels: app: scalardb-sample-app template: metadata: labels: app: scalardb-sample-app spec: containers: - name: scalardb-sample-app image: <account-id>.dkr.ecr.<region>.amazonaws.com/scalardb-sample-app:latest ports: - containerPort: 8080
各定義の内容は以下の通りです。
| key | 説明 |
|---|---|
| apiVersion | Kubernetes のリソースの API バージョン。 |
| kind | リソースの種類。 ※ここでは、アプリケーションのデプロイメントを定義するリソースタイプ。 |
| metadata.name | デプロイメントの名前。 |
| metadata.namespace | デプロイメントを作成する Kubernetes 名前空間。 |
| spec.replicas | 作成する Pod の数。 |
| spec.selector.matchLabels.app | Pod を識別するためのラベル。 ※app:scalardb-sample-app に一致する Pod が管理対象。 |
| spec.template.metadata.labels.app | Pod のテンプレート。 ※Pod に付けるラベル app:scalardb-sample-app。 |
| spec.template.spec.containers.name | コンテナを識別するためのユニークな名前。 |
| spec.template.spec.containers.image | 使用する Docker イメージのリポジトリとタグ。 ※ここでは、AWS ECR に保存されたイメージ。 |
| spec.template.spec.containers.ports.containerPort | コンテナがリッスンするポート番号。 |
6.6.2 デプロイ
以下のコマンドを実行して、作成したdeployment.yamlを利用してKubernetesにアプリケーションをデプロイします。
kubectl apply -f deployment.yaml
6.7 アプリケーションのサービス(APIエンドポイント)を確認
以下のコマンドを実行して、アプリケーションがデプロイされていることを確認します。
kubectl get svc -n scalardb
以下のようにscalardb-sample-appという名前のレコードが出力されれば、アプリケーションは正しくデプロイされています。
※scalardb-sample-appのEXTERNAL-IPについてはアプリケーションの実行時に利用します。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE scalardb-cluster ClusterIP 10.100.200.1 <none> 50051/TCP 10m scalardb-sample-app LoadBalancer 10.100.200.50 a1b2c3d4.elb.amazonaws.com 8080:32222/TCP 5m
7. アプリケーションの実行
最後に、正しくアプリケーションが実行できること、および複数のDBに接続できていることを確認するためにアプリケーションのAPIを実行します。
<EXTERNAL-IP>には、6.7にて確認したアドレスを指定します。
7.1 データ登録
以下のcurlコマンドでアプリケーションのAPIを利用してデータを登録します。
curl -X POST http://<EXTERNAL-IP>:8080/orders \ -H "Content-Type: application/json" \ -d '{ "order_id": "order-001", "customer_id": "customer-001", "product_id": "product-001", "quantity": 2, "price": 1000 }'
問題なくレコードが登録された場合は以下のように返却されたjsonが出力されます。
{ "status": "success" }
7.2 データ取得
以下のcurlコマンドでアプリケーションのAPIを利用してデータを取得します。
curl -X GET http://<EXTERNAL-IP>:8080/orders/order-001 \ -H "Content-Type: application/json"
問題なくレコードが取得できた場合は以下のように返却されたjsonが出力されます。
{ "order_id": "order-001", "customer_id": "customer-001", "product_id": "product-001", "quantity": 2, "price": 1000, "status": "completed" }
7.3 DB上でのデータ確認
以下の想定通りに接続先DBでデータが登録されていることを確認します。
ordersテーブル:Amazon RDS (PostgreSQL)
productsテーブル:DynamoDB
customersテーブル:DynamoDB
7.3.1 Amazon RDS (PostgreSQL)のordersテーブルの確認
下記コマンドでordersテーブルのレコードを確認します。
<RDS-endpoint>には、4.1.2 RDS への接続確認にて利用したRDSのエンドポイントを設定します。
psql -h <rds-endpoint> -U scalardb -d postgres -c "SELECT * FROM orders;"
レコードが登録されていれば、以下のように登録されているレコードが表示されます。
order_id | customer_id | product_id | quantity | price | status ----------+-------------+------------+----------+-------+-------- order-001 | customer-001 | product-001 | 2 | 1000 | completed
7.3.2 DynamoDBの確認
DynamoDBのproductsテーブル・customersテーブルのレコードを確認します。
・productsテーブル
以下のコマンドを実行してproductsテーブルのレコードを取得します。
aws dynamodb scan --table-name products
レコードが登録されていれば、以下のように登録されているレコードが表示されます。
{ "Items": [ { "product_id": { "S": "product-001" }, "name": { "S": "Product 001" } } ], "Count": 1, "ScannedCount": 1 }
・customersテーブル
以下のコマンドを実行してcustomersテーブルのレコードを取得します。
aws dynamodb scan --table-name customers
レコードが登録されていれば、以下のように登録されているレコードが表示されます。
{ "Items": [ { "customer_id": { "S": "customer-001" }, "name": { "S": "Customer 001" } } ], "Count": 1, "ScannedCount": 1 }
終わりに
今回はクイックスタートのアプリケーションをAWSのEKS上にデプロイするという作業を行いました。
一部ScalarDB Cluster特有の設定はありますが、その他についてはDockerやKubernetesの知識がある程度ある方であれば何も難しいことはなく進められる内容かと思います。
アプリケーションがScalarDBでのDBアクセスに対応している必要はありますが、手軽に分散データベースへのアクセスができるようになる、かつ単一障害点にならずスケーラブルなDBアクセスが実現できると言う点で、とてもメリットが大きいと感じました。
今後、ScalarDBではベクトルデータベースのサポート、レコード単位でのアクセス制御もロードマップとして予定されております。
弊社の得意領域とのシナジー効果も高くなっていくと考えられるため、今後の動向に注目しておきたいと思います。
引用文献
[1] Deploy ScalarDB Cluster on Amazon Elastic Kubernetes Service (EKS), 閲覧日時:2025年2月16日
https://scalardb.scalar-labs.com/ja-jp/docs/latest/scalar-kubernetes/ManualDeploymentGuideScalarDBClusterOnEKS
参考記事
Deploy ScalarDB Cluster on Amazon Elastic Kubernetes Service (EKS), 閲覧日時:2025年2月16日
https://scalardb.scalar-labs.com/docs/latest/scalar-kubernetes/ManualDeploymentGuideScalarDBClusterOnEKS
Amazon EKS とは, 閲覧日時:2025年2月15日
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/what-is-eks.html