Hello, I’m Sarah Yukie Soeda, an AI Engineer at Ridge-i. Recently, I have been studying about LLM application development using LangChain. In this article, I would like to share the some of the capabilities of LangChain. I hope this would be helpful to anyone who would like to dive into the world LangChain!
Table of Contents
- RAG theory
- Indexing & Retrieval
- Generation
- Basic set-up
- Package installations
- API Key
- Module imports
- Data loading & summarization
- Loading different data (e.g. pdfs, youtube, webpages)
- Summarization
- Chunking (Splitting)
- Create vector embeddings
- RAG application
- Code walk through of applying RAG
RAG theory
Let's first start with some theory. A inherent limitation of Large Language Models (LLMs) is that they only have access to the data that they were original trained on, while lacking access to recent data or private data. To address this constraint, a powerful feature called retrieval augmented generation (RAG) is used in LangChain. RAG connects LLMs to external documents, and is largely divided into the stages of indexing, retrieval, and generation (Figure 1).
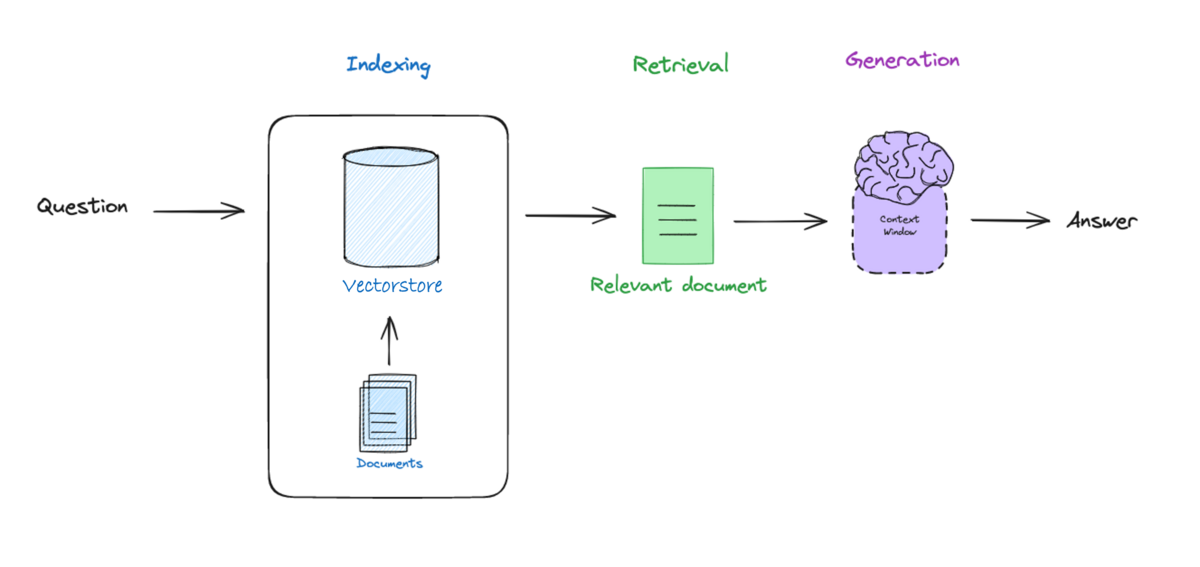
Figure 1. Overview of RAG. Image Source from [1].
Indexing involves processing data and converting them into representations that can be easily stored and searched in what is called the vectorstore. Retrival searches for the most-relevant documents to the question (or input) and returns them to the LLM model. Generation is the process of a LLM creating an answer based on the question and retrieved documents. Let's next dive into each of the topics of indexing, retrieval and generation.
Indexing & Retrieval
Documents must undergo preprocessing to convert them into a retrievable form (Figure 2). Documents are split up into manageable parts called chunks. These chunks are compressed into vector embeddings that can be easily be compared for similiarity in their semantic meanings.
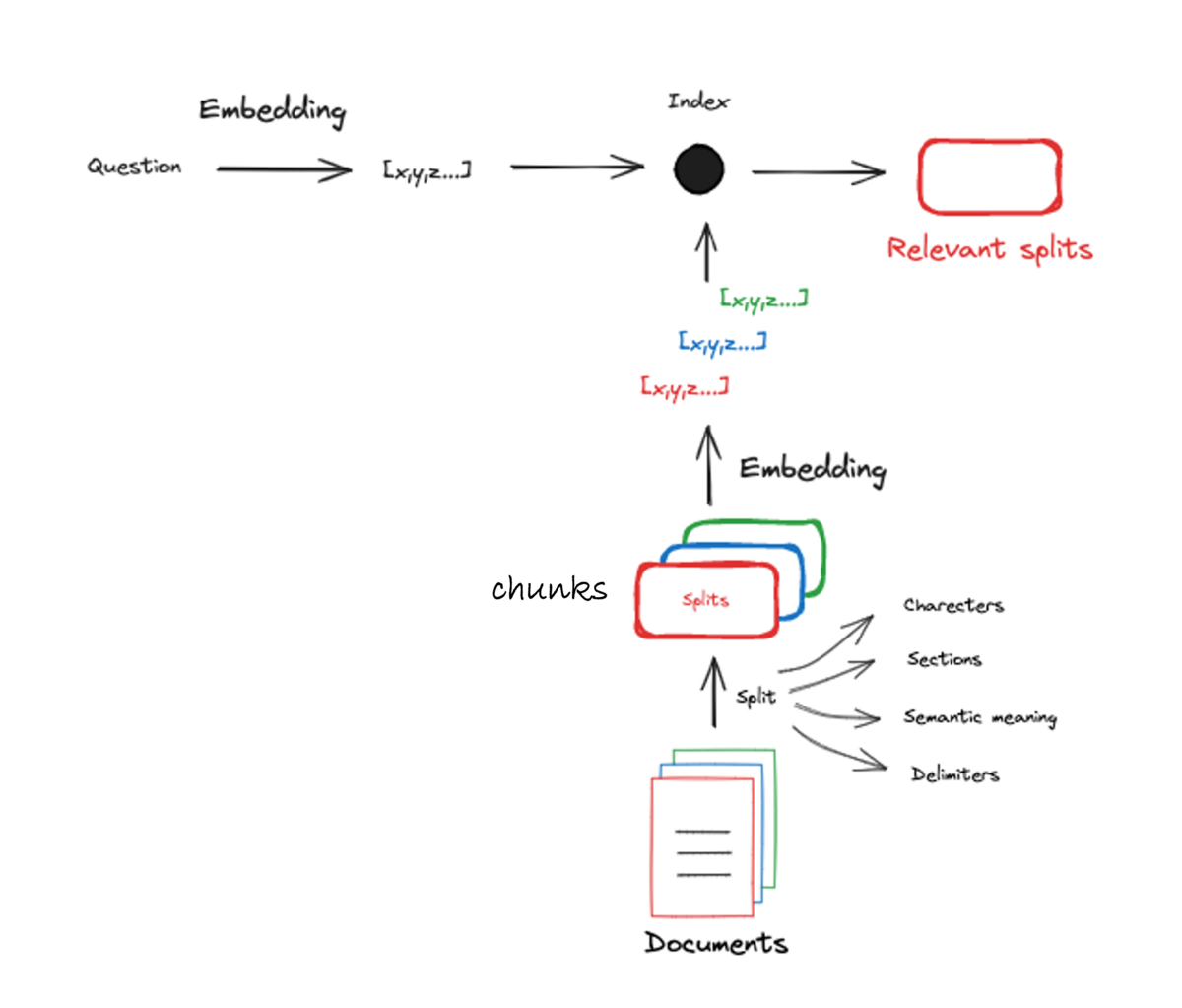
Figure 2. Preprocessing documents into numerical representations. Image Source from [1].
This concept of search similiarity of vector embeddings can best be understood by visualizing our vector embeddings in space. For this, we will assume our vector embeddings have 3 values that can be projected in a 3D space (Figure 3). The location of vector embeddings in this space is determined by their semantic information. Thus, vector embeddings with similiar semantic information will be closely located to each other. These concepts are used by vectorstores to perform a high dimensional search to find the most similiar documents to the question.

Figure 3. Similarity search on vector embeddings to find documents most relevant to question. Image Source from [1].
Generation
After indexing and retrieval, the next step is to generate an answer from the LLM. This involves using a prompt template that takes in the retrieved relevant documents and question, and outputs instructions to the LLM on how to answer the question. This answer can undergo post-processing, such as parsing to customize the output (Figure 4).
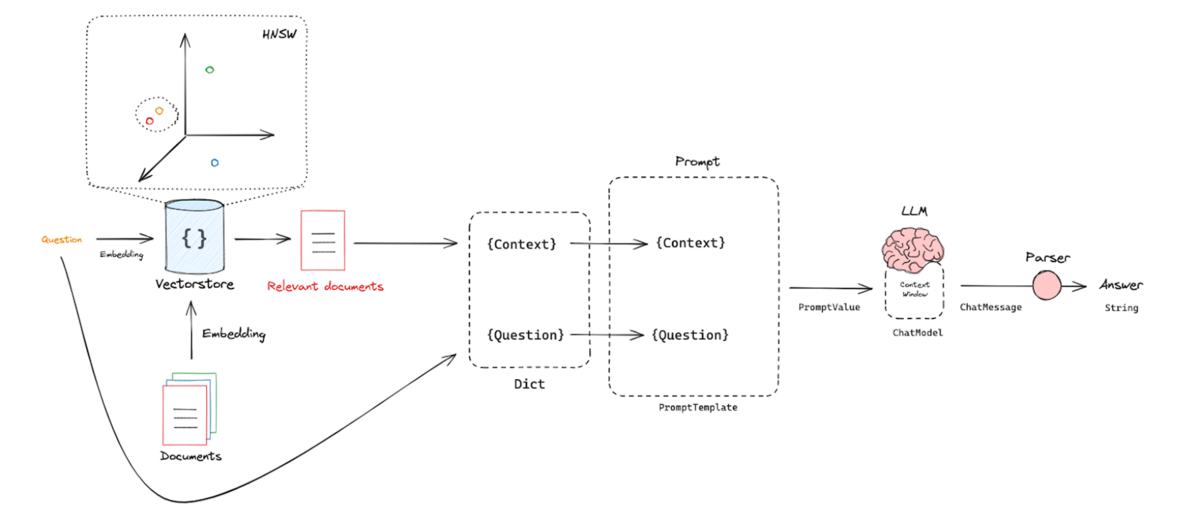
Figure 4. Generating an answer using a prompt template, relelvant documents and question, to instruct LLM how to answer the question. Image Source from [1].
Now that we have covered a bit of theory behind RAG let's try writing some code to implement what we have learned. Here is an overview of the workflow of the topics we will cover from document loading to RAG implementation. It may look a little intimidating at first, but we will go through it with some code bit-by-bit.
Figure 5. Overview of our workflow to create a LLM application. Image adapted from [2].
Basic set-up
First, let's set-up our enviroment. We will need to install the following packages and import some modules (Note: add "!" if you are installing within jupyter notebook).
! pip install python-dotenv openai langchain from dotenv import load_dotenv, find_dotenv import openai import os
Next, let's set-up our OPEN API key. If you don't have a API key you can obtain one from here: https://platform.openai.com/account/api-keys. To load your API key, you can follow either Option 1 or Option 2.
Option (1): Store API KEY in the environment.
os.environ['OPENAI_API_KEY'] = 'sk...'
Option (2): Store OPEN API Key in .env file and load into enviroment. For more info on how to create .env file refer to: https://saturncloud.io/blog/how-to-set-environment-variables-in-jupyter-notebooks-a-guide-for-data-scientists/
_ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY'] # load api key
We will next set-up LangSmith to record our runs. LangSmith is a useful platform to debug, test, and monitor LLM apps. For this step, you will need to obtain an API langchain key (Note: This step is optional, but is useful to keep track and review runs.)
os.environ['LANGCHAIN_TRACING_V2'] = 'true' os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com' os.environ['LANGCHAIN_PROJECT'] = 'PROJECT_NAME' # Change to your project name os.environ['LANGCHAIN_API_KEY'] = 'ls...' # Your LangSmith API key
Data loading & summerization
Now that we have our enviroment set-up let's practice loading some data. LangChain has the flexiblity to load different data types and sources into a format that can easily be worked with (Figure 5). In this section, we will practice using LangChain document loaders to load pdfs, html webpages, and youtube videos.
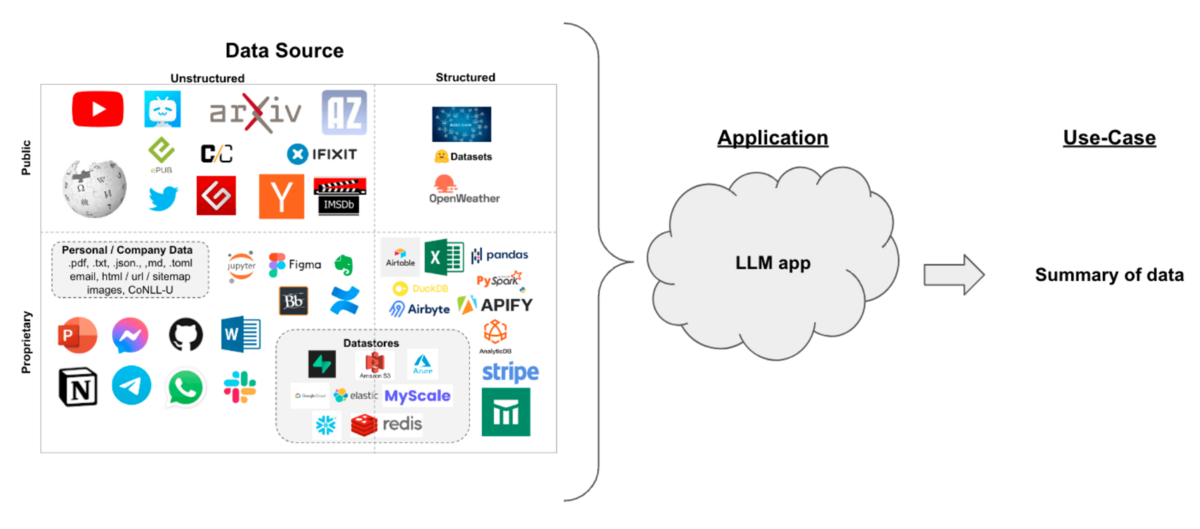
Figure 6. Schematic of different data types and sources that can be imported using LangChain. Image Source from [2].
Let's try to load a pdf. We will load a pdf of a press release from Ridge-i titled "PR_231019_SUBARU様_生成AIサービス.pdf" using the following code. (Note this pdf file has been saved previously in the directory).
from pathlib import Path from langchain.document_loaders import PyPDFLoader file_path = os.getcwd() + '/docs/pdf/press_release/■PR_231019_SUBARU様_生成AIサービス.pdf' pdf_loader = PyPDFLoader(file_path) pdf_pages = pdf_loader.load()
Next, let's do some pre-processing steps to join the pages of the pdf (by default pages are separated when loaded), and summarize the content using LangChain's preassembled chains LLMChain and StuffDocumentsChain to make the content concise and retrieve the main points from the press release. To use these chains we will create a model object to set-up our LLM, and a prompt template as demonstrated in the code below.
Here we will be using OpenAI model gpt-3.5-turbo. ChatOpenAI contains a parameter temperature that controls the randomness of the output. We will set it to zero to make the output focused and deterministic. In the prompt template, we provide instructions to create a summary of the pdf contents. The model object and prompt template are fed into LLM Chain, which are inputted into StuffDocumentsChain to create the final stuff chain. We can now run stuff chain with invoke command to create our pdf summary.
from langchain.docstore.document import Document
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
# 1. Join pdf pages
pdf_docs = Document(page_content="/n/n".join([page.page_content for page in pdf_pages]))
# 2. Create summary of pdf
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt_template = """Provide a concise summary of the following text delimited by triple backquotes.
```{text}```
"""
prompt = PromptTemplate.from_template(prompt_template)
llm_chain = LLMChain(llm=model, prompt=prompt)
stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="text")
pdf_summary = stuff_chain.invoke([pdf_docs])
pdf_summary['output_text'] # To view the summary content
We suceeded in loading our first pdf file! Now let's practice loading data from websites. We will scrape data from Ridge-i's webpage: https://ridge-i.com/career/about/. Let's set-up the path to the html file. (Note this html file has been saved previously in the directory).
html_path = os.getcwd() + '/docs/html/Ridge-iについて|リッジアイ|Ridge-i Career.html'
We can use BeautifulSoup library to extract only the main text from the html page. To do this, we will specifiy 'p' to find all text contained within <p> tags of the html text (HTML <p> tag defines a paragraph).
from bs4 import BeautifulSoup with open(html_path, "r", encoding="UTF-8") as file: soup = BeautifulSoup(file) # Convert html file to beautifulsoup object html_content = str(soup.find_all('p'))
Also, we can pre-process our html text to remove anything we consider to be noise. For example, here we remove \
tag itself from the html text. Lastly, as we did before we will summarize the content of our html text using our stuff chain we defined before.
html_content = html_content.replace('<p>', '') html_content = Document(page_content=html_content) html_summary = stuff_chain.invoke([html_content]) html_summary['output_text'] # To view the summary content
Now that we finished loading our html pages, let's next try to load a youtube video! We will view and load a transcript video from the Ridge-i Youtube channel using the code below.
from IPython.display import YouTubeVideo from langchain.document_loaders import YoutubeLoader YouTubeVideo("iKc8-rlqefg", width=500) loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=iKc8-rlqefg", language=["ja"]) yb_transcript = loader.load()

Let's try to summarize the content of our video using our stuff chain from before.
yt_summary = stuff_chain.invoke(yb_transcript)
This results in the following error.
BadRequestError: Error code: 400 - {'error': {'message': "This model's maximum context length is 4097 tokens. However, your messages resulted in 4821 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
We find that we can no longer use the stuff chain due to the total number of tokens, the building blocks of words, exceeding the context length or the maximum tokens allowed by our model. We can check the amount of tokens that the youtube transcript equates to using the tiktoken library.
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
tokens = encoding.encode(yb_transcript[0].page_content)
tokens_count = len(tokens)
print(f"Total tokens: {tokens_count}")
We find that the number of tokens is 4794, and indeed exceeds the max amount of tokens allowed by our model. To handle data with large number of tokens we can use Map-Reduce. The method of Map-Reduce is illustrated below (Figure 7). In constrast to stuff chain we have been using so far, Map Reduce splits the documents into smaller pieces, summarizes each piece, and creates a single final summary based on all the summaries.
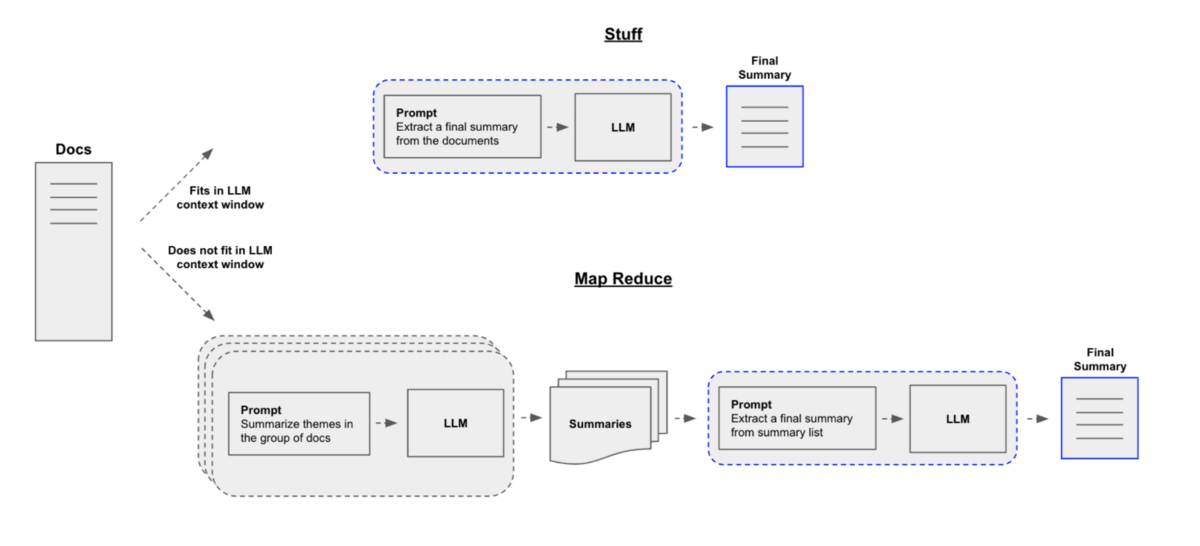
Figure 7. LangChain methods for summarization: Stuff vs. Map Reduce. Image Source from [2].
We can implement Map-Reduce on our youtube transcript using the following code.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import ReduceDocumentsChain, MapReduceDocumentsChain
# Create text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 100,
length_function = len,
)
# Split text
yt_docs = text_splitter.create_documents([yb_transcript[0].page_content])
# Create Map template & chain
map_template = """The following is a set of documents
{docs}
Based on this list of docs, please identify the main themes
"""
map_prompt = PromptTemplate.from_template(map_template)
map_chain = LLMChain(llm=model, prompt=map_prompt)
# Create Reduce template & chain
reduce_template = """The following is set of summaries:
{docs}
Take these and distill it into a final, consolidated summary of the main themes.
Make sure to include main points and important details, such as name of people and topics.
"""
reduce_prompt = PromptTemplate.from_template(reduce_template)
reduce_chain = LLMChain(llm=model, prompt=reduce_prompt)
# Create summary chain
combine_documents_chain = StuffDocumentsChain(llm_chain=reduce_chain,
document_variable_name="docs"
)
# Create reduce chain (Combine and iteratively reduce mapped documents)
reduce_documents_chain = ReduceDocumentsChain(combine_documents_chain=combine_documents_chain,
collapse_documents_chain=combine_documents_chain,
token_max=4000,
)
# Create map reduce chain (Create final summary)
map_reduce_chain = MapReduceDocumentsChain(llm_chain=map_chain,
reduce_documents_chain=reduce_documents_chain,
document_variable_name="docs",
return_intermediate_steps=True,
)
# Retrieve summary
yt_summary = map_reduce_chain.invoke(yt_docs)
yt_summary['output_text']
Great, so now we sucessfully loaded a pdf, youtube video and html page and summarized the contents. Let's now preprocess our documents to convert them into a retrievable form (as we discussed in Indexing Section).
To preprocess our data, we first need to split up our documents into managable chunks. We will split the pdf, youtube video and html page documents into chunks. We will use the text splitter from the previous step to split up our documnets.
# Collect pdf chunks pdf_chunks = text_splitter.split_text(pdf_summary['output_text']) # Collect youtube chunks yt_chunks = text_splitter.split_text(yt_summary['output_text']) # Collect html chunks html_chunks = text_splitter.split_text(html_summary['output_text']) # Combine chunks docs = pdf_chunks + yt_chunks + html_chunks
Now that we created our chunks, we will convert these chunks into vector embeddings using an embedding model. We will use OpenAIEmbeddings for our embedding model as shown in the code below. We can see that the model creates 11 embeddings with a character size of 1536 for our first embedding.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
embeddings = embeddings_model.embed_documents(docs)
print('embedding #: ', len(embeddings), 'embedding size:',len(embeddings[0]))
embedding #: 11 embedding size: 1536
RAG application
Let's now take our vector embeddings, load them into a vectorstore, and build a retrieval to retrieve relevant documents to the question. To do this, first we will need to create Document objects out of out documents. Next, we create a vectorstore, a retriever and a prompt. To string together these components we will create a custom chain using LangChain Expression Language (LCEL). The following code shows how to implement these steps. In the rag chain we use StrOutputParser() to output the final output as a string.
from langchain.vectorstores import Chroma from langchain_core.runnables import RunnableParallel, RunnablePassthrough from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate # Convert chunks to Document objects documents_batch = [Document(page_content=t) for t in docs] # Create vectorstore vectorstore = Chroma.from_documents(documents_batch, embeddings_model) # Create retriever retriever = vectorstore.as_retriever() # Create prompt template = """ You are experienced in answering questions about Ridge-i company. You can only answer about a specific TOPIC written below. Answer the question based only on the provided context: <context> {context} </context> TOPIC: {input} """ prompt = ChatPromptTemplate.from_template(template) # Set-up chain setup_and_retrieval = RunnableParallel( {"input": RunnablePassthrough(), "context": retriever} ) # Output response from model as string output_parser = StrOutputParser() # Create chain rag_chain = setup_and_retrieval | prompt | model | output_parser # LangChain Expression Language (LCEL)
Now we can try asking a question to our model! We see that our model outputs a response that is closely related to our question.
response = rag_chain.invoke("What is the mission of Ridge-i?")
response
We receive the following response: "The mission of Ridge-i is to combine cutting-edge technology and business skills to provide innovative solutions and create a new future. They aim to understand existing technologies and integrate them with advanced technologies to solve challenges. They also seek professionals who can contribute to the delivery of advanced technology and make a social impact. The company's goal is to create a professional group that can effectively utilize the potential of advanced technology."
We can check LangSmith to see what documents were retrieved and fed into our LLM. The documents are shown below. We can see that most contents are related in some form to our question. It is possible to evalualate how relevelant these documents are to our question, and/or how well our RAG performs, but that is a topic for another article!

Great we have succeeded in implementing our first RAG! We see that in just a few lines of code we can easiliy implement a RAG using LangChain. Here we have only scratched the surface of the capalities of LangChain, but hopefully this article has provided you with a good starting point to develop your own LLM applications! Good luck on the next steps of your LangChain journey.
Image Resources
[1] LangChain Youtube channel: https://www.youtube.com/@LangChain
[2] LangChain Documentation: https://docs.langchain.com/
Tutorial Resources
- RAG theory: LangChain Youtube RAG from Stratch series https://www.youtube.com/@LangChain/playlists
- LangChain for LLM Application Development: https://www.deeplearning.ai/short-courses/langchain-for-llm-application-development/
- Summarization: https://python.langchain.com/docs/use_cases/summarization
- Data loading: https://pub.towardsai.net/hands-on-langchain-for-llm-applications-development-documents-loading-43d889644845
- Beautiful Soup: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation: https://towardsdatascience.com/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation-4e9bd5f6a4f2
- LangChain Expression Language (LCEL): https://python.langchain.com/docs/expression_language/