Hi! This is Ridge-institute and in today's article, Motaz Sabri will share with us his explorations on the person reidentification (ReID) model's ability to generalize across datasets and their distortion robustness. Person ReID is frequently utilized in security and surveillance services. Many current-day research and solutions consider the performance of the ReID model on clean datasets while ignoring the performance of the ReID model in various image distortion scenarios (motion blur, pixelation, rain, etc.). Insights from surveillance videos will undoubtedly be impacted by such factors in real-world circumstances. Therefore, it is crucial to understand the ReID model's resilience in such situations. First, we will try to understand the distortion effect on neural networks in general and then focus on ReID distortions on both inputs and features. we will also evaluate the Feature Erasing and Diffusion Network (FED), a method that handles Non-Pedestrian Occlusions and Non-Target Pedestrians simultaneously to achieve robust person ReID through feature distortion.
Background
Adding noise as a means of augmentation has been utilized in many types of research. It has proven to increase model generalization. Adding untailored noise, however, may corrupt the learning process and lead to crippling the model’s ability to extract proper features. Injecting noise in testing data to evaluate model resilience and robustness has recently gained significant attention. Noise has also been used in the generative model such as diffusion models through a forward diffusion stage and a reverse diffusion stage by gradually perturbing the input data over several steps by adding Gaussian noise. In this work, we will talk about noise as a general regularizer, its effect on data augmentation, and as a measure to evaluate the ReID model’s stability and finally discuss how it was incorporated in a diffusion based ReID model.
Noise as a regularizers
Since neural network regularization has been introduced, many techniques have been applied to generalize networks beyond the training data including L1 and L2 regularization, dropout, and preventing the co-adaptation of detectors feature [1, 2, 3]. Many regularizing methods focus on optimizing network target function during the training. One commonly used approach is introducing a training criterion that discourages converging the network into building a complicated solution and suppresses the number of effective weights by directing the learning algorithm toward a solution with the least possible amount of zero weights such as weight decay [8]. Other approaches encourage less co-adapting between units and reduce overfitting such as Dropout [3]. One more powerful method of improving neural network generalization ability is noise injection. many mathematical modeling clarifies why the learning process improves upon noise injection into specific joints within the network [4, 5].
Theory
The effect of injecting noise enhances learning and improves the generalization of numerous neural networks. The placement of the injection contributes to the learning process and suppresses feature learning when there is uncertainty while it allows higher learning when the model is more certain as proven by many works [6, 7, 9, 10, 11]. For instance, in [11], the noise-related term that appears as they derive the learning equation of a simple MLP regularizes the learning by weakening the learning abilities when the activations are indefinite and encourages the learning otherwise. Early noise placement (earlier layers) enables higher diversification for the inputs while later placement allows higher diversity for the extracted features. Figure 1 shows weights visualization with and without noise injection while Figure 2 shows TSNE chart for multiple noise placements.
Illustrations
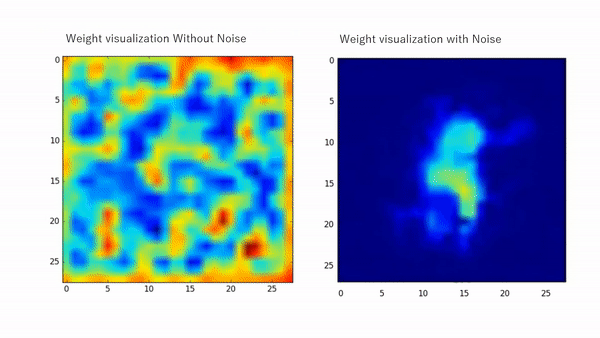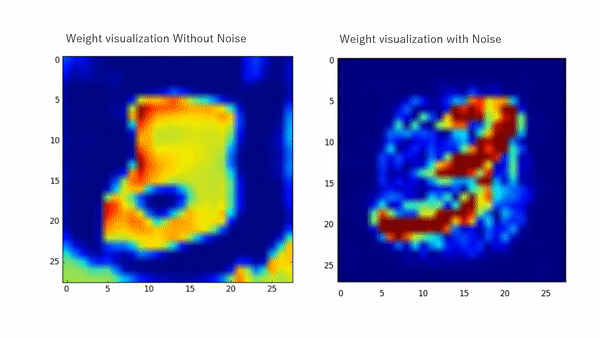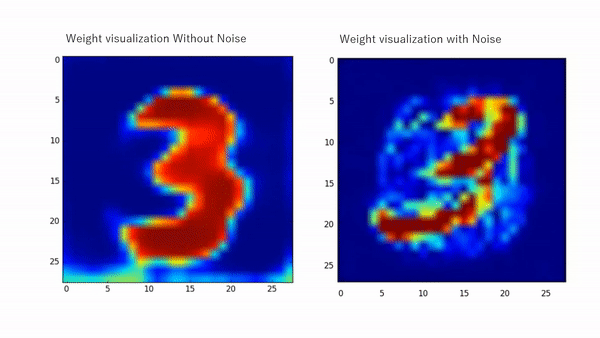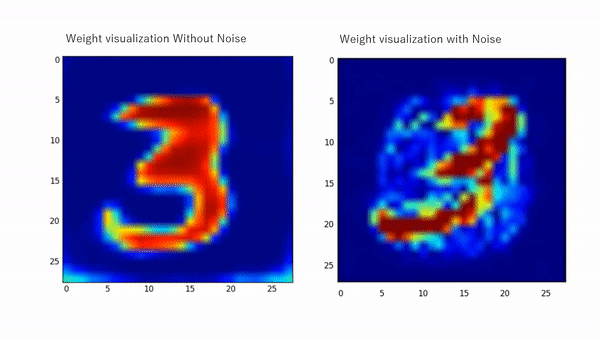

The same behavior in a more complicated design can be seen in Figure 3 for the Duke dataset as we injected noise during training in certain branches of a triplet network. This allowed the retrieval of more fine features for reidentification.

Noise as a robustness measure
Let’s get more specific and try to focus on the models’ robustness when noise is introduced to input data for the ReID task. For this task, it’s common to use mAP (mean average precision). Now we have defined the evaluation criteria, let’s define our noise to be Gaussian, Shot, Impulse, or Speckle. There are other types that are also essential to evaluate model robustness such as blurring and pixelation. Let’s finally define where to place our noise. In our evaluation, we use the query and gallery for testing, where for each image in the query you find similar persons in the gallery set. Due to the particularity of the task, let’s define three test settings: both query and gallery are images contaminated with noise (Noisy scenarios and Noisy training data respectively); the only query is contaminated with noise, and finally only gallery is contaminated.
Theory
Experimental results show that existing ReID methods perform poorly in noisy scenarios. In Figure 4 we can see via the Market-1501 dataset and its contaminated version Market-1501-C that there is no obvious positive correlation between the performance of existing models on clean datasets and the performance on noisy scenarios.

it can be observed that Part-level-based ReID methods such as PCB and RRID can achieve good performance on both clean datasets and noisy datasets. To a certain extent, it shows that the mining of local features can help improve the model generalization. This brings an interesting question, what if we train a model to learn how to avoid noise and focus only on the uncontaminated part?
This is proposed in [12] by introducing their local data enhancement algorithm. They replaced a random patch of pixels in an image with random noise during the model training phase. Randomness erasures have been verified on multiple ReID datasets to improve the performance of the model on clean datasets. They also applied Random Patches (replacing random patches from an image with random patches from another image during the model training phase). It has also been shown to improve model performance on clean datasets. those two augmentations affect the model's ability to mine local information more efficiently.
In [12], they also utilized Vision Transformer architecture for the ReID task, and it shows robustness under a variety of noise scenarios. It’s worth mentioning that a mixture of two persons (Random Patch) can significantly improve the robustness of the model. When combined with Random Patch and random erasing the model achieve the best performance.
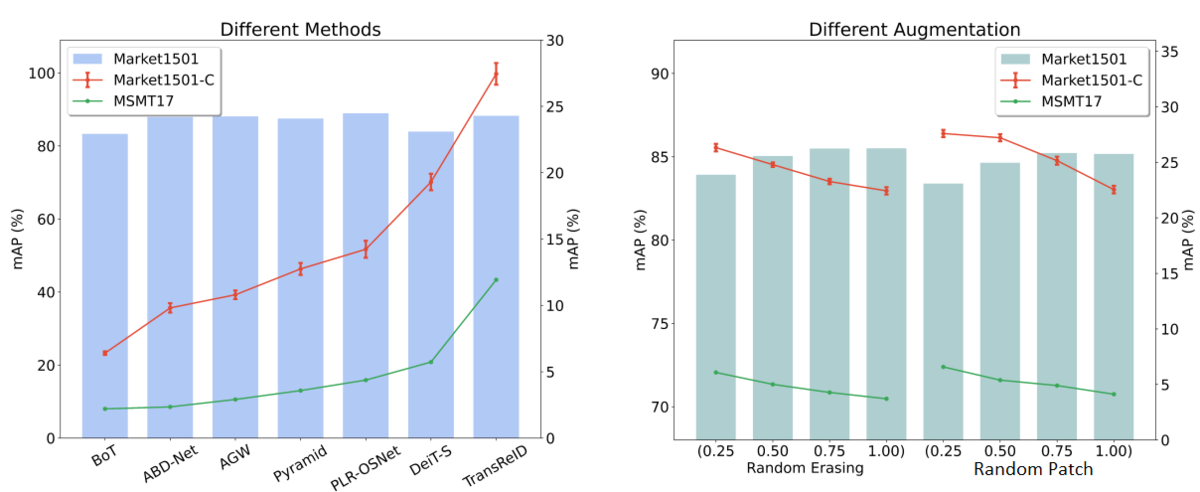
From their work, we find that there is a correlation between the model's noise robustness and generalizability across datasets in the person re-identification task. In Figure 5, they conducted validation experiments with different ReID methods (left) and different data augmentation methods (right), all models are trained on Market-1501, and the red line is the noise on the Market-1501 test set, the green line is the performance on the MSMT17 test set. The experimental results show that there is a strong linear positive correlation between introducing noise (through erasing and patching) and the robustness of the model and the generalizability across datasets in the person re-identification task.
Illustrations
Noise as a means of learning
We have dealt with noise as a regularizer and a resilience measure. Is it possible to introduce noise to a model to detect all the corruption presence in the input? In other words, can we train a noise detector? Just like diffusion models which are latent variable models capable to synthesize high-quality images, let’s consider introducing noise in the learning process and teach the model how to reconstruct the person fully without any noise. This is proposed in [13] but instead of fusing noise in the network, they diffused the pedestrian representation with other memorized features and synthesizes no target person features in the feature space.
They started by simulating Non-Pedestrian Occlusions on pedestrian images and removing the occlusion features by the proposed Occlusion Erasing Module (OEM) using the Non-Pedestrian Occlusions augmentation strategy to generate accurate occlusion masks.
Design
The OEM is constructed by 4 sub-modules corresponding to each body part. Each sub-module is constructed by two fully connected (FC) layers, one normalization layer, and one Sigmoid function. The normalization layer is placed between the FC layers, and the Sigmoid function is located at the end. The first FC layer compresses the channel dimension to a quarter of the original one, aiming to wipe off the characteristic information and reserve the semantic ones. The final Sigmoid function will output the regressed occlusion scores for each part feature. The occlusion masks from the Non-Pedestrian Occlusion augmentation strategy are adopted to supervise the training of OEM.
Occlusion score guidance by OEMs ensures feature diffusion processing is done primarily on visible body parts to ensure the quality of synthesized non-target pedestrian features. As a result, only features of significance are synthesized. Those features are of great resilience to occlusions of numerous types and robust against noise and feature contaminations.
Then, through a learnable cross-attention mechanism, their new feature diffusion module (FDM) diffuses the pedestrian representation with other memorized features and synthesizes Non-target Pedestrian features in the feature space.
FDM is a modified cross-attention module based on the standard architecture of the transformer. Firstly, it suggests conducting Memory Searching Operation between across regions and then calculating the attention matrix and corresponding part features. Each element of the attention matrix indirectly indicates the connections between the key and the query, and the cross-product operation between the value and the attention matrix will generate the diffused features. The design is shown in Figure 6.

The multi-head attention operation is of great significance in this module. Since features have many similar patterns with the input image and these patterns are distributed randomly in numerous feature centers, the multi-head operation will split each center into multi parts and generate attention weights for each part individually, thus ensuring more patterns like target pedestrian and sufficient unique patterns of Non- target pedestrian can be aggregated. In this way, the multi-pedestrian images can be simulated on the feature level.
After the cross-attention operation, they utilized the post-layer normalization feed-forward network (a simple neural network with two fully connected layers and one activation function). Next, the occlusion scores generated by OEM are adopted for weighted summation between the transformed features. This ensures the characteristics of Non-target pedestrians are only added on human parts rather than pre-recognized object occlusion parts, improving the realness and quality of the diffused features. Besides, the weighted residual operation can stabilize the training process. Moreover, the proposed FDM only serves as an auxiliary module for learning and is discarded during the inference stage, thus incurring little inference computational overhead.
Joint optimization of OEM and FDM in the proposed FED network can greatly improve the model's ability to perceive target pedestrians and mitigate the impact of none target pedestrians and Non-target occlusion. This robustness increases the approach’s reliability and its generalization capacity to a high level. Experiment with occluded and holistic person ReID benchmark shows FED efficiency. Results are shown in the Table 1 for Occlude-DukeMTMC dataset. Table 2 shows results on Market-1501 and DukeMTMC-reID datasets.
Table 1: Performance comparison with state-of-the-art methods on Occlude-DukeMTMC, Occluded-ReID and Partial-REID datasets Cited from [13].
| O-Duke | O-REID | P-REID | ||||
| Method | R@1 | mAP | R@1 | mAP | R@1 | mAP |
| PCB[14] | 42.6 | 33.7 | 41.3 | 38.9 | 66.3 | 63.8 |
| RE[15] | 40.5 | 30 | - | - | 54.3 | 54.4 |
| FD-GAN[16] | 40.8 | - | - | - | - | - |
| DSR[17] | 40.8 | 30.4 | 72.8 | 62.8 | 73.7 | 68.07 |
| SFR[18] | 42.3 | 32 | - | - | 56.9 | - |
| FRR[19] | - | - | 78.3 | 68 | 81 | 76.6 |
| PVPM[20] | 47 | 37.7 | 70.4 | 61.2 | - | - |
| PGFA[21] | 51.4 | 37.3 | - | - | 69 | 61.5 |
| HOReID[22] | 55.1 | 43.8 | 80.3 | 70.2 | 85.3 | - |
| OAMN[23] | 62.6 | 46.1 | - | - | 86 | - |
| PAT[24] | 64.5 | 53.6 | 81.6 | 72.1 | 88 | - |
| ViT Baseline[25] | 60.5 | 53.1 | 81.2 | 76.7 | 73.3 | 74 |
| TransReID[26] | 64.2 | 55.7 | 70.2 | 67.3 | 71.3 | 68.6 |
| FED[13] | 68.1 | 56.4 | 86.3 | 79.3 | 83.1 | 80.5 |
| FED[13] | 67.9 | 56.3 | 87 | 79.4 | 84.6 | 82.3 |
Table 2: Performance comparison with state-of-the-art methods on Market-1501 and DukeMTMC-reID datasets. Cited from [13]
| Market-1501 | DukeMTMC-reID | |||
| Model | Rank-1 | mAP | Rank-1 | mAP |
| PT[26] | 87.7 | 68.9 | 78.5 | 56.9 |
| PGFA[16] | 91.2 | 76.8 | 82.6 | 65.5 |
| PCB[14] | 92.3 | 77.4 | 81.8 | 66.1 |
| OAMN[23] | 92.3 | 79.8 | 86.3 | 72.6 |
| BoT[28] | 94.1 | 85.7 | 86.4 | 76.4 |
| HOReID[22] | 94.2 | 84.9 | 86.9 | 75.6 |
| PAT[24] | 95.4 | 88 | 88.8 | 78.2 |
| ViT Baseline[3] | 94.7 | 86.8 | 88.8 | 79.3 |
| TransReID[3] | 95 | 88.2 | 89.6 | 80.6 |
| FED[13] | 95 | 86.3 | 89.4 | 78 |
Illustrations
Using the FED model, we conducted our experiments on external data we collected at the Ridge-i office to evaluate model generalization capacity. The samples were collected under a variety of lighting conditions, shooting angles, backgrounds, occlusion levels (Humans and objects), camera types, and distances from the camera. The model manages to identify subjects correctly regardless of the occlusion or feature contamination as shown in Figure 7.

The FED can handle cases with Non-pedestrian occlusion and Non-target pedestrian occlusion for occluded person ReID. Guided by the image-level Non-pedestrian occlusion augmentation strategy, the occlusion erasing module is trained to eliminate Non-pedestrian occlusion features based on the predicted occlusion scores. Subsequently, the feature diffusion module performs feature diffusion between pedestrian representations and memorized features, synthesizing Non-target occlusion characteristics in the feature space.
Conclusion
Generalization is one of the most critical challenges in deep neural networks, and there are various types of regularization methods to improve generalization performance. Injecting noises to hidden units during training, adding noise to the training data, or even altering features with noise, are known as successful methods. In this article, we demonstrated the effectiveness of these methods in machine learning and specified their importance in the ReID model’s robustness. We applied These methods to our own data and observed consistent improvement over numerous tasks. We believe that the proposed methods may improve many other deep neural network models.
References
- .Y. Bengio, “Deep Learning of Representations: Looking Forward,” arXiv.org, vol.7978, pp.1–37, May 2013.
- .Z. Lian, X. Jing, X. Wang, H. Huang, Y. Tan, and Y. Cui, “DropConnect Regularization Method with Sparsity Constraint for Neural Networks,” Chinese Journal of Electronics, vol.25, no.1, pp.152–158, 2016.
- .B. Cao, J. Li, and B. Zhang, “Regularizing neural networks with adaptive local drop,” International Joint Conference on Neural Networks, pp.1–5, 2015.
- .E.A. Smirnov, D.M. Timoshenko, and S.N. Andrianov, “Comparison of Regularization Methods for ImageNet Classification with Deep Convolutional Neural Networks,” AASRI Conference on Computational Intelligence and Bioinformatics, vol.6, pp.89–94, 2014.
- .N. Tripathi and A. Jadeja, A Survey of Regularization Methods for Deep Neural Network, International Journal of Computer Science and Mobile Computing, IJCSMC, vol.3, no.11, pp.429–436, 2014.
- .H. Inayoshi and T. Kurita, “Improved Generalization by Adding both Auto-Association and Hidden-Layer-Noise to Neural-Network-Based-Classifiers,” Machine Learning for Signal Processing, 2005 IEEE Workshop, pp.141–146, 2005.
- .B. Poole, J. Sohl-Dickstein, and S. Ganguli, Analyzing noise in AutoEncoders and deep networks, arXiv:1406.1831. URL: http://arxiv.org/abs/1406.1831, June 2014.
- .C.S. Leung, H.-J. Wang, and J. Sum, “On the Selection of Weight Decay Parameter for Faulty Networks,” IEEE Trans. Neural Netw., vol.21, no.8, pp.1232–1244, 2010.
- .T. Kurita, H. Asoh, S. Umeyama, S. Akaho, and A. Hosomi, “A Structural Learning by Adding Independent noises to Hidden Units,” Proc. IEEE International Conference on Neural Networks, IEEE World congress on Computational intelligence, vol.1, pp.275–278, 1994.
- .K. Audhkhasi, O. Osoba, and B. Kosko, “Noise-enhanced convolutional neural networks, Neural Networks,” vol.78, pp.15–23, 2016.
- Sabri, T. Kuriata , Effect of Additive Noise for Multi-Layered Perceptron with AutoEncoders, IEICE Transactions on Information and Systems, 2017, E100.D 巻, 7 号, p. 1494-1504.
- Minghui & Wang, Zhiqiang & Zheng, Feng. (2021). Benchmarks for Corruption Invariant Person Re-identification.
- Zhikang & Zhu, Feng & Tang, Shixiang & Zhao, Rui & He, Lihuo & Song, Jiangning. (2021). Feature Erasing and Diffusion Network for Occluded Person Re-Identification.
- .Y. Sun, L. Zheng, Y. Yang, Q. Tian, and S. Wang, “Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline),” in ECCV, 2018, pp. 480– 496.
- .Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” in AAAI, vol. 34, no. 07, 2020, pp. 13 001–13 008.
- .Y. Ge, Z. Li, H. Zhao, G. Yin, S. Yi, X. Wang, and H. Li, “Fd-gan: Pose-guided feature distilling gan for robust person re-identification,” in NIPS, 2018, pp. 1229–1240.
- .L. He, J. Liang, H. Li, and Z. Sun, “Deep spatial feature reconstruction for partial person re-identification: Alignment free approach,” in CVPR, 2018, pp. 7073–7082.
- .L. He, Z. Sun, Y. Zhu, and Y. Wang, “Recognizing partial biometric patterns,” arXiv preprint arXiv:1810.07399, 2018.
- .L. He, Y. Wang, W. Liu, H. Zhao, Z. Sun, and J. Feng, “Foreground-aware pyramid reconstruction for alignment free occluded person re-identification,” in ICCV, 2019, pp. 8450–8459.
- .S. Gao, J. Wang, H. Lu, and Z. Liu, “Pose-guided visible part matching for occluded person reid,” in CVPR, 2020, pp. 11 744–11 752.
- .J. Miao, Y. Wu, P. Liu, Y. Ding, and Y. Yang, “Pose-guided feature alignment for occluded person re-identification,” in ICCV, 2019, pp. 542–551.
- .G. Wang, S. Yang, H. Liu, Z. Wang, Y. Yang, S. Wang, G. Yu, E. Zhou, and J. Sun, “High-order information matters: Learning relation and topology for occluded person reidentification,” in CVPR, 2020, pp. 6449–6458.
- .P. Chen, W. Liu, P. Dai, J. Liu, Q. Ye, M. Xu, Q. Chen, and R. Ji, “Occlude them all: Occlusion-aware attention network for occluded person re-id,” in ICCV, 2021, pp. 11 833– 11 842.
- .Y. Li, J. He, T. Zhang, X. Liu, Y. Zhang, and F.Wu, “Diverse part discovery: Occluded person re-identification with partaware transformer,” in CVPR, 2021, pp. 2898–2907.
- .S. He, H. Luo, P.Wang, F.Wang, H. Li, andW. Jiang, “Transreid: Transformer-based object re-identification,” ICCV, 2021.
- .J. Liu, B. Ni, Y. Yan, P. Zhou, S. Cheng, and J. Hu, “Pose transferrable person re-identification,” in CVPR, 2018, pp. 4099–4108.
- .J. Miao, Y. Wu, P. Liu, Y. Ding, and Y. Yang, “Pose-guided feature alignment for occluded person re-identification,” in ICCV, 2019, pp. 542–551.
- .H. Luo, Y. Gu, X. Liao, S. Lai, and W. Jiang, “Bag of tricks and a strong baseline for deep person re-identification,” in CVPRW, 2019, pp. 0–0