Hello, I am Bu Hongyu, working as an Artificial Intelligence Engineer at Ridge-i Inc. In this article, I will show you how to quickly finetune Stable Diffusion (SD) model with just a few training images (5-10 images) and generate images in your own style.
Introduction to SD model
SD model is a machine learning model that is trained to progressively denoise random Gaussian noise to generate images. SD achieves Latent Diffusion to reduce memory and computational costs and generate high-resolution images by applying a diffusion process on a low-dimensional latent space instead of the actual pixel space. For more details, please refer to the original paper [1].
Although SD model can generate excellent images of various styles according to the input text, it may not know what you want to generate in advance, such as new objects, new characters, and new art styles. In such cases, you need to finetune the model with new data in order to generate the desired images.
Implementation
This article introduces three methods (Textual Inversion, Dreambooth, LoRA) to finetune SD model, and compares their performance. The scripts, model, and dependencies are available on GitHub [2]. The environment setup part is skipped in this article. Note that the parameters used for finetuning may not be optimal and are only provided for reference.
The implementation is carried out on a Laptop PC equipped with 16GB RAM and 16GB NVIDIA GeForce RTX 3080 Ti Laptop GPU.
For finetuning, the new images are downloaded from [3] as shown below:






Textual Inversion
Feature: Textual Inversion [4] is a method that finetunes the text embedding part to map text prompt to the most suitable Embedding Vector, directing SD model to output images accordingly. This method does not modify the original SD model, instead, it produces a mapping record of a text prompt and its corresponding vector, which is a very small data, typically in the tens of KB.
Train: The following command is used for training. "<cat-toy>" is the new text prompt, "gradient_accumulation_steps" is set to 4, "max_train_steps" is set to 400 and "learning_rate" is set to 5e-4.
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=400 \
--learning_rate=5e-4 \
--scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0
Dreambooth
Feature: Dreambooth [5] is a method that directly finetunes the entire original SD model to adjust the model's output results. The finetuning process establishes a relationship between the new data (such as cat toy images) and the new text prompt (such as "<cat-toy>"). The trained result is a completely new model, which can be very large, usually about 2-4GB.
Train: The following command is used for training. "a photo of <cat-toy>" is the new text prompt, "gradient_accumulation_steps" is set to 1, "max_train_steps" is set to 400 and "learning_rate" is set to 1e-6. The training process does not use prior-preservation, and "gradient_checkpointing" and "use_8bit_adam" are added in order to run on a 16GB GPU.
export MODEL_NAME="CompVis/stable-diffusion-v1-5"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of <cat-toy>" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--use_8bit_adam \
--learning_rate=1e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400
LoRA
Feature: LoRA [6] is a method that freezes the weights of the original SD model and adds new layers with rank-decomposition weight matrices for training. By inserting the trained weights of these new layers into the original SD model, it builds the correlation between the new data (such as cat toy images) and the new text prompt (such as "<cat-toy>"). LoRA training is faster and uses less VRAM than Dreambooth since the new layers have significantly fewer parameters than the original model. The trained result is also much smaller, usually about 8-150MB.
Train: The following command is used for training. "a photo of <cat-toy>" is the new text prompt, "gradient_accumulation_steps" is set to 1, "max_train_steps" is set to 400 and "learning_rate" is set to 5e-4.
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of <cat-toy>" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-4 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400
Inference
Here is the inference code for generating new images using three trained results. Two types of text prompts ("A <cat-toy> backpack" and "<cat-toy> on the beach") are used to generate images separately.
from diffusers import StableDiffusionPipeline, DiffusionPipeline, DPMSolverMultistepScheduler
import torch
model_id = "path-to-your-trained-model"
# pipe for Textual Inversion and Dreambooth
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
# pipe for LoRA
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.to("cuda")
pipe.unet.load_attn_procs(model_id)
# text prompt: "A <cat-toy> backpack" or "<cat-toy> on the beach"
prompt = "new-text-prompt"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("result.png")
Results
Here are the results generated with the text prompt "A <cat-toy> backpack" in the order of Textual Inversion, Dreambooth, and LoRA, from left to right.



Here are the results generated with the text prompt "<cat-toy> on the beach" in the order of Textual Inversion, Dreambooth, and LoRA, from left to right.



Benchmark
Here is the benchmark for three finetuning methods.
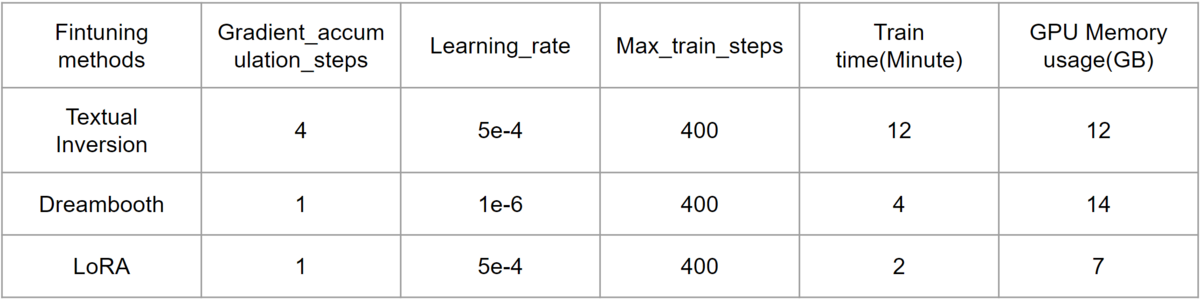
Insights from my experience
Textual Inversion: Higher "gradient_accumulation_steps" or "max_train_steps" can generate the images that match the style of the training images.
Dreambooth: High "learning_rate" or "max_train_steps" may lead to overfitting.
LoRA: It can be trained with higher "learning_rate" than Dreambooth and can fit the style of the training images in the shortest time compared to other methods.
Conclusion
This blog introduces three methods for finetuning SD model with only 5-10 images. Among them, LoRA is recommended for consumer GPUs as it can be trained faster with less computation. It would be interesting to explore more creative images through the fusion of multiple LoRA models.
Lastly
Ridge-i is actively hiring for various positions. Casual interviews are also possible, so if you are interested, please contact us.
References
[1] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models”, In 2022, CVPR.
[2] https://github.com/huggingface/diffusers/tree/main/examples
[3] https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion#cat-toy-example
[4] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or, “An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion”, In 2022.
[5] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman, “DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation”, In 2023, CVPR.
[6] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, “LoRA: Low-Rank Adaptation of Large Language Models”, In 2021.