Hi! This is Ridge-i research and in today's article Motaz Sabri will share with us some of our findings obtained here regarding Ridge-I Person Re-Identification (Re-ID) which is a formidable task considering it aims to retrieve a given person among all the gallery images captured across different cameras. The complexity of the problem comes from large variations of postures, occlusion cases, clothes, background clutter, misdetection, etc. Deep Convolutional Neural Network (CNN) expanded the Re-ID performance with better discrimination and robustness in many scenarios. Some recent deep Re-ID methods [Bai et al., 2018, Zhang et al., 2017, Sun et al., 2018, Qian et al., 2018] have achieved surpassing state-of-the-art identification rates and mean average precision that matches the human abilities in some complicated cases.

Background
Recent researches proposed locating significant body parts from images to represent local information. A body part region contains a small percentage of local information from the whole body. It also contains distractions by other related or unrelated information outside the regions. Those distractions are filtered by locating salience regions allowing more focus on identities and complementing global features. Therefore, highlighting partial regions is a key element in the learning process [Yao,2019, Li et al., 2017]. This happens by either enhancing features by middle-level attention on salient parts [Zhao et al., 2017, Liu et al., 2017, Liu et al., 2019, Li et al., 2018] and feeding strong structural information such as empirical knowledge about human bodies [Sun et al., 2018, Zhang et al., 2017] or strong learning-based pose estimation [Su et al., 2002, Zhao et al., 2017] . What is common among these approaches is their sensitivity to pose or occlusion variations. They are also unable to generalize for all the discriminative parts as they focus on specific regions with fixed semantics. As a result, they consist of multiple components that are not end-to-end learning processes, which increases the difficulty of learning.
In our work, we propose an end-to-end global and local person Re-ID feature learning strategy for refined granularities without guided part locating operation. Our approach balances the attention between intra and inter representations to learn adaptive weights. The person image comes with raw global information, striping it will result in features of local parts to concentrate more on finer discriminative information per stripe. Using CNN, we can also extract more fine-grained saliency for local features of smaller part regions. Those regions of high importance come from equally split stripes that do not necessarily belong to regions with specific semantics. As the number of horizontal stripes increases, the granularity of discriminative responses becomes finer.
Inspired by this observation, we design the Refined Granularity Network (RGN), which consists of local and global expert branches with parameters from the intermediate stage of a backbone CNN. Every branch learns discriminative features by minimizing losses that correspond to the given branch. In each local expert branch of RGN, we split pooled feature maps into part regions varying the numbers of stripes to learn local feature presentations independently, motivated by the findings of [Wen et al., 2016, Wang et al., 2018]. We used equally divided parts for local representation to design an end-to-end learning process. Besides outperforming other methods, our approach also increases the robustness against viewpoint and scale changes due to its high feature localization ability.
CNNs have been used in many researches for embedding learning for person Re-ID tasks in the literature. From the use of Siamese network architecture to generate body part embedding to learn Re-ID to proposing ID-Discriminative Embedding (IDE) with ResNet-50 backbones offering high-performance levels that influenced many modern deep Re-ID systems for embeddings extraction. Intermediate embedding of image pairs are always analyzed to characterize links between local parts in a handcrafted mechanism. Many attempts to enhance the generalization of Re-ID embedding extraction were performed such as introducing domain-guided dropout. Other researchers tried bringing a re-ranking strategy into Re-ID tasks that allowed results ranking for better accuracy. Optimized feature localization and learning strategy are key factors of success in most of the state of the art methods.
Feature localization
The latest embedding learning strategies have enhanced Re-ID accuracy under a variety of conditions. Many of these strategies have been designed to emphasize discriminative features and suppress irrelevant ones for better learning. Some works use the human part or pose information to infer the regions with high importance for extracting foreground embedding. Some works focus on learning based on spatial positions or channels in end-to-end frameworks. In our work, we propose to combine the local representations from parts of images to improve Re-ID effectiveness. In the literature of part-based learning, researchers utilize body structural information, region proposal methods, and spatial attention to enhance representation learning.
Joint learning strategy
Our learning approach uses horizontal stripes as part regions for local embedding learning and outperforms state-of-the-art methods. We use a joint learning strategy by using both softmax and triplet losses in our proposed method. The most common loss functions are classification losses and metric losses in deep Re-ID systems training.
Refined Granularity Network
A deep CNN can gain discriminative abilities on different body parts based on their inherent semantic definition. Those abilities are enhanced by adding attention mechanisms to highlight salient components. To further marginalize the distraction of unrelated patterns in person Re-ID targets in complicated scenes, higher activations must be concentrated on the main body of the subject. This is conventionally achieved in CNN by narrowing represented regions and learn local features by training via classification loss. As a result, responses on the local feature maps gradually cluster with a variety of sizes on some salient semantic patterns depending on the size and the importance of the corresponding region.
The generation of the feature map requires analyzing high representative regions by focusing on specific patterns for representations and overcoming the limitation of information in restricted regions [Wang et al., 2018]. One major limitation in the feature extraction process is its unavoidable focus on basic granularity diversity regardless of empirical prior knowledge. As a result, it becomes intuitively hard to discriminate people's identities based on the information brought by local regions. Using the classification learning strategy enforces the feature extraction to focus on more generalizable identity granularity, consequently pushing the training to explore useful refined details among relatively limited information. With a sufficient level of granularity, CNN can capture details with the most discriminative information. Motivated by the above analysis, we propose the Refined Granularity Network (RGN) architecture to combine global and multi-local granularity feature learning to achieve higher person Re-ID scores for subjects under a variety of scenarios.
The Design
The architecture of RGN is shown in the figure below. The feature encoder of our network is ResNet-50 which helps to achieve competitive performances in many ReID systems [Bai et al., 2018, Wen et al., 2016, Zhao et al., 2017]. The global branch learns global feature representations without part locating operation or any partition information. while the other two local branches share the same design with the global branch without down-sampling operations to maintain proper areas of receptive fields for local features. We refer to the lower branches as local branches.

The output feature maps of the local branches are split uniformly into several horizontal stripes. We observed that the column vectors in these horizontal stripes are clustered together forming many outliers that are similar within the same stripe compared to other stripes. This phenomenon suggests that these outliers within a designated stripe are inherently more consistent with column vectors compared to other parts. Inspired by this observation we conduct an adaptive partition to refine the original uniform partition, and the outliers are reassigned to the parts they are closest to, resulting in refined granularity with enhanced within-part consistency. To achieve this, branches two and three have the subbranch concept which refers to the subbranch of the parent branches. The subbranch contains partitions of the raw feature maps. During inference, the lower subbranches are concatenated and later combined with local and global features to form a comprehensive representation of subjects. Our choice of the loss function for the training phase is a combination of softmax loss for classification and triplet loss for metric learning. They are widely used in various deep Re- ID methods. We define our identification task as a multi-class classification problem.
Creating expert branches seems to be reasonable as the global and local representations cannot be both learned in one single branch. The reason might be that the branches sharing similar network architecture only react to different levels of detailed information on images. As a result, when multiple granularities are fed to one mixed single branch, the features might dilute the importance of detailed information.
In our proposal, Global Branch has a larger receptive field and GAP captures coarse features from subject images. The branch with more partitions will learn finer representation for pedestrian images. Therefore, features learned by the second and third branches tend to be local but fine. Consequently, learning different preferences can cooperatively supplement low-level discriminating information to the common backbone parts, which is the reason for performance boosting in any single branch. Usage of triplet loss on global features only is due to triplet loss tendency to confuse the model during training under constant variation of local regions.
If you wish to know more, additional technical details can be found in the paper mentioned in this blog intro.
Experiment and evaluation
We evaluated our proposed method using four Re-ID datasets: Market1501, MSMT17, DukeMTMC ReID, and CUHK03. In our experiments, we evaluated the Cumulative Matching Characteristics (CMC) at Rank-1 and Mean Average Precision (mAP) on previously mentioned datasets. Using CMC Rank-1 means the mean probability that a target is classified correctly within the first response is given by the classifier. If a person is to be re-identified, CMC at first position holds the normalized number of times that its name appears at least within one response from the re-identification algorithm. the mAP is used to evaluate the overall performance. For each query, we calculate the area under the precision-recall curve. Then, we calculate the mean value of average precision of all queries, which considers both recall and precision of the used method. On Market1501 and MSMT17 datasets following the common practices, our experiments included single and multiple query modes. Single query setting means one of the query images is selected each time and then the same person with the query image is found among the set of gallery images. Multiple query setting selects and matches multiple images instead of a single image. We validate the effectiveness of our proposed method and show the comparisons in the following table.
 In comparison with the approaches that leverage human semantics through attention on human part segmentation and those which learn attention from input images themselves, our method significantly outperforms most of them. On CUHK03 (Detected), Market1501, and the largescale MSMT17 datasets, in comparison with all other approaches, RGN achieves the competitive performance which outperforms the second-best approach by 0.1%, 1.8%, and 1.6% in mAP accuracy, respectively. The introduction of our method consistently brings significant gains for the state-of-the-art performance for a variety of datasets. According to the following table:
In comparison with the approaches that leverage human semantics through attention on human part segmentation and those which learn attention from input images themselves, our method significantly outperforms most of them. On CUHK03 (Detected), Market1501, and the largescale MSMT17 datasets, in comparison with all other approaches, RGN achieves the competitive performance which outperforms the second-best approach by 0.1%, 1.8%, and 1.6% in mAP accuracy, respectively. The introduction of our method consistently brings significant gains for the state-of-the-art performance for a variety of datasets. According to the following table:
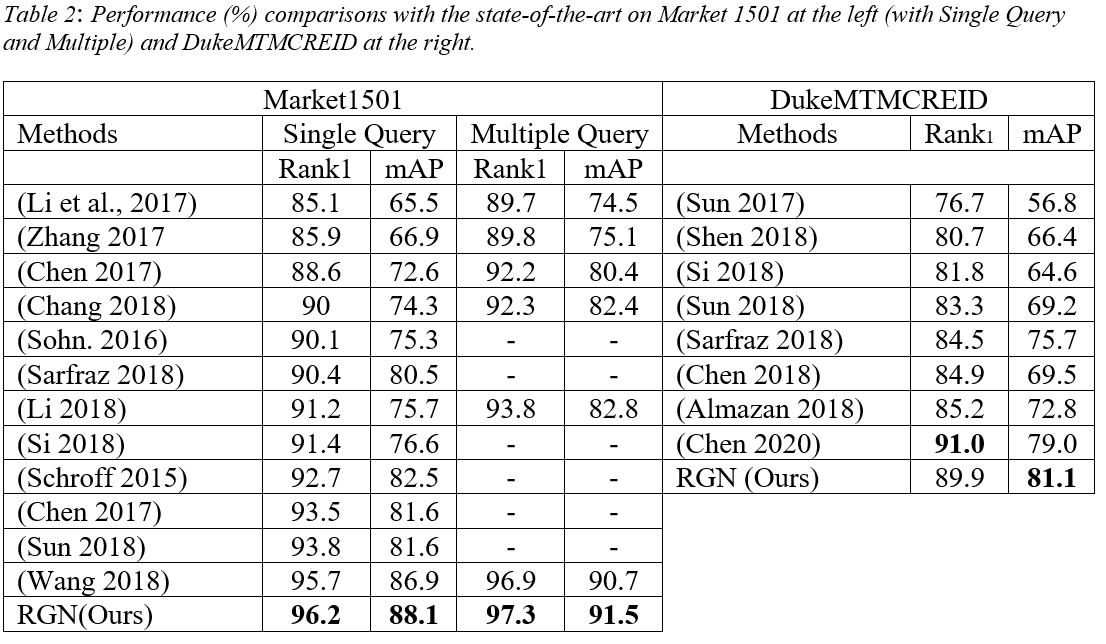 RGN method outperforms the most state-of-the-art methods via mAP criteria on the challenging ReID datasets.
RGN method outperforms the most state-of-the-art methods via mAP criteria on the challenging ReID datasets.
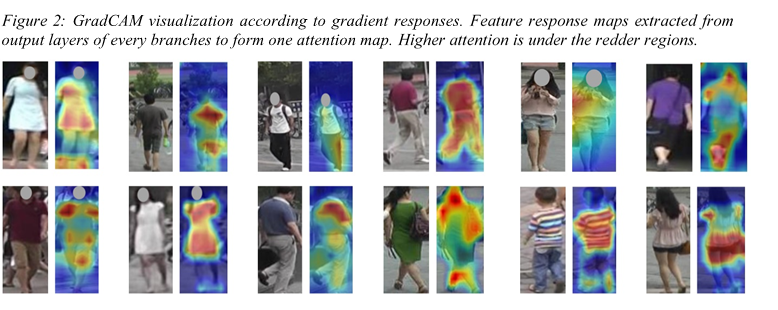
Visually, our enhancements can be seen in the following figure as it shows top-10 results for some given query pedestrian images from all datasets used in our experiments. The first row shows great robustness regardless of the pose, brightness, or gait of the given subject, RGN features can robustly represent discriminative information of their identities. The second query shows the false positive case in which 2 people who look very similar are confused. The similarity is not only in clothing but also the posture. The third row holds an interesting observation in which the background has a significant change in its content yet RGN managed to react correctly to most of the results. The last row shows the subject carrying a wearing coat being tracked correctly regardless of the posture or camera view. This is the result of using local features, which establish relationships among salient parts that can be used as robust identification elements.

We applied the Grad-CAM tool to our model for the qualitative analysis. Grad-CAM tool highlights the regions that the network considers important. The following figure shows the generated masks of RGN covering the person regions accurately for some samples. The loss functions of our attention lead the network to focus on discriminative body parts in addition to global features. The attention focuses on the person and ignores the background. In comparison with another attention approach that does not consider relations between body parts, our attention sharply focuses on the body regions with discriminative information. Consequently, this benefits the knowledge extraction from the global scope structural information. An interesting observation is that the head has usually low attention. This is due to the low amount of information embedded in it while differentiating different persons due to the low resolution of the given images.
Ablation Analysis
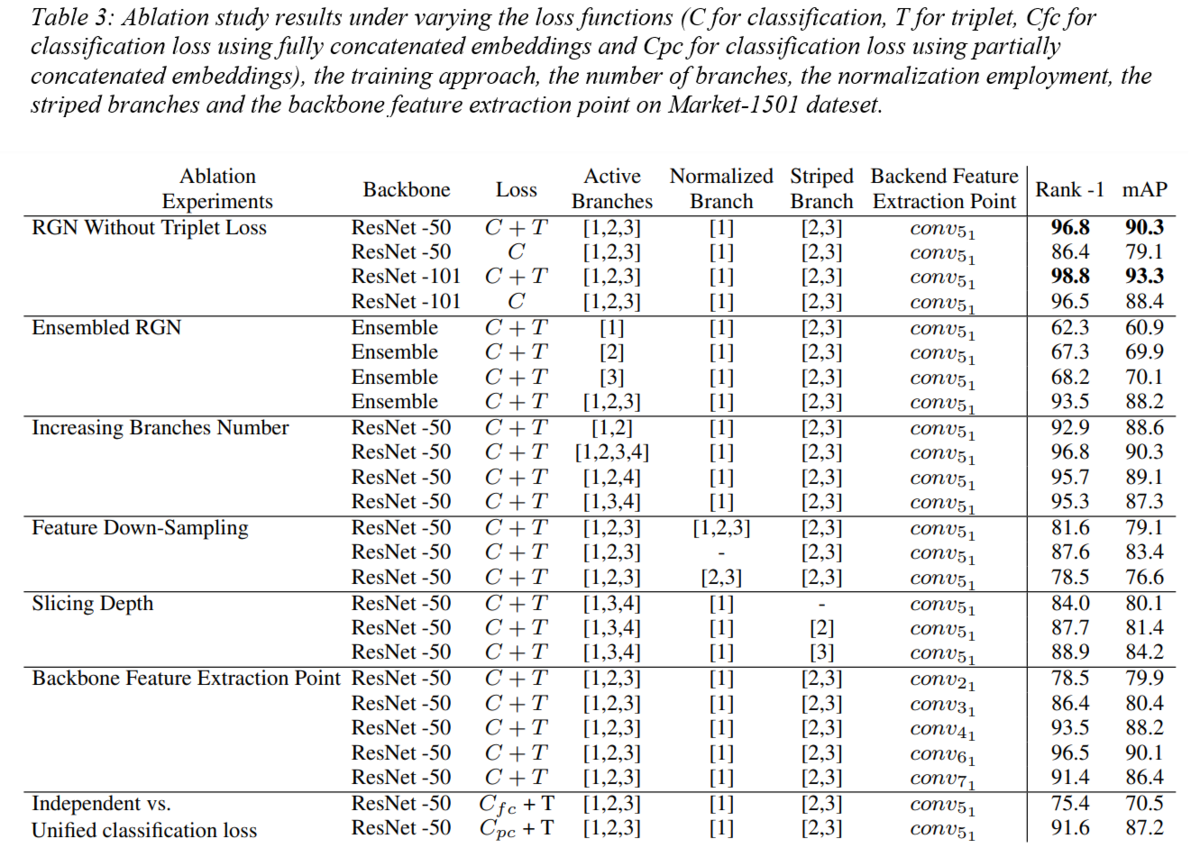
We performed additional ablation experiments with different settings on the Market-1501 dataset in single query mode to evaluate RGN performance. To conduct a fair comparison, we use the same set of configurations for RGN mentioned in the experiment section and report the average performance with our settings. We separately analyze each component of the model in the following discussion.
RGN without triplet loss
In our experiment, we utilize both the triplet loss and classification loss. Previous work show robustness in the joint training of those two loss functions. When removing the metric loss from our proposal, the model acts as a standard ResNet-50 model. As seen in the ablation experiments table at the end of this section- RGN without triplet loss set of experiments, the effect reduces Rank-1 by -10.4% and mAP by -11.2%. We tried other versions of ResNet (training with both losses and later without triplet loss) such as the ResNet-101 model. It can be clearly observed that a deeper feature extractor brings a considerable performance boost. However, the removal of the triplet loss reduces Rank-1 by -2.3% and mAP by -4.9% from the Resnet-101 results. The improvement on mAP is significant compared to Rank-1 accuracy, which shows ranking effects of triplet learning and metric learning in general. Triplet loss also helps to capture more salient details to meet the margin condition compared to softmax loss. In general, the above results show that our proposal does not depend on extra weights from additional branches and has the robust capability for feature extraction on person Re-ID task.
Ensembled RGN
Our proposal of a multi-branch network is a slight variation of an ensemble model that consists of multiple networks trained dedicatedly to act like every individual branch. The collaboration among multiple branches adds a better performance than ensemble learning in our case. This is the result of our experiment on three independent ResNet-50 networks trained separately to replicate the corresponding configuration of our three branches. We analyze the ensemble effect through general and limited scopes as seen in the table below- Ensembled RGN set of experiments. For the general scope, we compare the overall performance of RGN with the ensemble of three single networks. The ensemble approach outperforms any single participating network. However, RGN still outperforms it with +3.3% / 2.1% on Rank-1 / mAP. This holds useful insights about the beneficial collaboration between branches that creates more discriminative feature representations than independent networks. On the limited scope, we evaluated subbranches of RGN with single networks in the corresponding setting of the branch. It was found that features from subbranches outperform that of the single networks. It is possible that the subbranches compensate each other against blind spots in their individual local tasks.
Increasing branches number
The multi-branch CNN architectures are very common for person Re-ID tasks. Our proposed method excels in learning representations with multiple granularities. Inspired by our results, many variants of the given architecture can be proposed as seen in the ablation experiments table- Increasing branches number set of experiments. One variation is to change the number of the local branches of our model. Initially, we used one global branch and two local branches. Using two branches for instance (one global and one local) causes direct drop for the Rank-1 / mAP= - 3.9% / 1.7%. Using 3 local branches (instead of 2 local branches) does not contribute in additional performance improvement. This design fits the current problem scope as the experiments illustrate.
Another variation is the number of subbranches that is found to affect the granularity of learning representations. To further investigate the effect of such variation, we add a fourth branch with four subbranches to it. Our experiments show no significant enhancement for the overall performance. Removing the third branch (while keeping the second and fourth branch) causes a gap in the granularity level that belongs to the third branch. As a result, the performance degrades by Rank-1 / mAP=-1.1% / 1.2%. We also remove the second branch and keep the third and fourth branches (while keeping the expanded subbranches configuration). This setup produces low performance with Rank-1 / mAP=-1.5% / 1.3%. We argue this setup takes away an essential overlap between a second branch and fourth partition from which essential discriminative information for Re-ID features is lost.
Feature down-sampling
We employ the down-sampling at the global branch and refrain from employing it on the local branches. Our experiment illustrates this configuration is constructive for feature learning. We evaluate other placements for the down-sampling to verify our choice. As seen in the ablation experiments table- Feature down-sampling set of experiments, placing down-sampling in every branch weakens the local branch abilities as they receive less information from the backbone. As a result the Rank-1 / mAP drops by -15.2% / 11.2%. Using no down-sampling in all branches affects the feature learning negatively. As a result, the Rank-1 / mAP drops by -9.2% / 6.9%. We also used the down-sampling at the local branches while removing it from the global branch. This configuration contributed the worst as the Rank-1 / mAP drops by -18.3% / 13.7%. Adding the down-sampling only to the global branch preserves the reception fields for local features while feeding the global branch with a sufficient amount of information to avoid overfitting. As a result feature maps in each branch are split into several stripes allowing more uniform learning of local feature representations. Consequently, this creates a balance between intra-attention and inter-attention allowing the learning of adaptive weights and features for the optimal person ReID.
Slicing depth
Slicing the feature maps of input images into several stripes generates local parts embeddings that can be merged into final representation. This creates refined parts that modify the mapping validation of part embedding and extracted features. The slicing procedure increases the localization abilities without prior labeling and as a result, it has the potential to replace body parts locating components if designed optimally. We use horizontal stripes as part regions for local embedding learning and later combine the local representations from parts of images to improve Re-ID effectiveness. We further investigate the slicing effect of the local branches as shown in the ablation experiments table- Slicing depth set of experiments. Removing the slicing from all local branches results in a drop in Rank-1 / mAP by -12.8% / 10.2%. Placing slicing on the second branch while removing it from the third branch results in performance degradation in Rank-1 / mAP by -9.1% / 8.9%. Finally, placing the slicing on the third branch while removing it from the second branch degrades the Rank-1 / mAP by -7.9% / 6.1%. This shows that the different numbers of partition slices introduce a diversity of content granularity. It can be also observed that the increase in the number of partitions generates local parts features that concentrate more on finer information in each part stripe. Our stripe procedure helps to locate salient and discriminative body parts while dispensing the unavoidable need for a keypoint localization component.
Backbone feature extraction point
The choice of backbone network must be aligned with the nature of features to be extracted. Another equally important choice is the layer to be used for feature extraction. We evaluate other extraction points to verify our choice. As seen in the ablation experiments table- Backbone feature extraction point set of experiments, using different feature extraction points has a direct impact on the overall performance. The early convolutions produce immature features and as a result, the Rank-1 / mAP drops. The further we advance into the backbone feature extractor the more mature the features become. It can be seen that the Rank-1 / mAP drop severity is less when compared to earlier layers. We notice choosing layers deeper than our main design results in another drop for Rank-1 / mAP. We argue this is due to the abstraction that happens to the features as they are fused deeper into the network. As a result, contextual information is not represented enough in the generated features and this explains the performance drop.
Independent Vs. unified classification loss
In our proposal, we feed the reduced 256-dimension local features in second and third branches in addition to raw global pooled 2048-dimension from all branches to softmax losses while feeding triplet losses with the globally reduced features. This learning scheme shows higher robustness when compared to the usage of one softmax loss function. As shown in the ablation experiments table- Independent Vs. unified classification loss set of experiments, using dedicated loss per local branch empowers its ability to detect salient features and therefore generates a better representation of the subject. Using one loss after concatenating all the reduced 256-dimension features and the globally pooled 2048-dimension features causes a performance drop with Rank-1 / mAP equals to -21.4% / 19.8%. Feeding the concatenated local features into one softmax loss function and feeding the concatenated global features into another softmax loss function does not result in better performance. This can be seen through the Rank-1 / mAP value given as -5.2% / 3.1%. This is strong evidence that the characteristics of every horizontal strip are unique and discriminative enough to independently represent regions of the given subject.
Feature learning
RGN model extracts both the global and local feature representations with multiple levels of granularities. The figure below shows the class activation maps for some input images, as seen from all the top branches in RGN. Response maps filter out most of the background as it has no useful content for identification. The responses from the global branch are mainly focused on main body parts while mostly excluding the face due to the absence of identification information in such blur images. On local branches, the global responses on the main body are ignored but additional attention is gained for more particular parts. The second branch shows more scattered responses on body parts highlighting pivotal semantic information. We can observe responses on a variety of body parts such as shoulders, elbows, and ankles in the third branch.
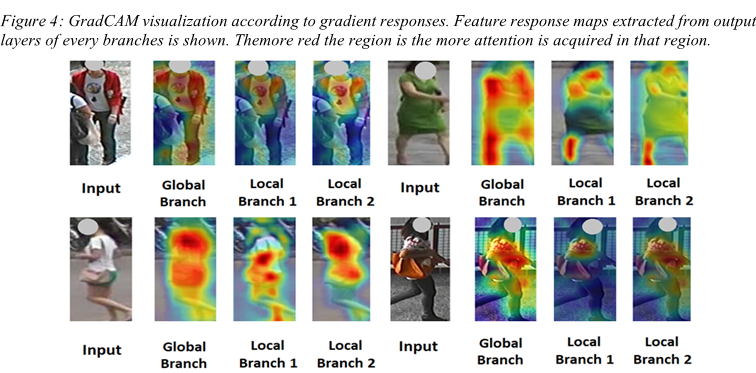
Conclusion
We propose the Refined Granularity Network (RGN), the multi-branch deep network for extracting features and learning discriminative representations in person re-identification tasks. Every branch becomes specialized in learning representation with a certain granularity of body region. RGN learns local features on horizontally split feature stripes, which are completely end-to-end without any part locating operations. Besides outperforming most state-of-the-art methods on several main-stream person Re-ID datasets, RGN generalizes well for many of the challenging cases in a variety of datasets.
We also performed ablation analysis providing more insight into the RGN model. Leveraging our unique exploitation of local and global features of human body images with inter and intra attention. It is in our interest to investigate more accurate and robust person ReID by incorporating trainable semantic human part parsing in our future work. It might also prove useful to investigate a learnable way to set the placement and size of the stripes proposed in this work.
さいごに
Ridge-iでは様々なポジションで積極採用中です. カジュアル面談も可能ですので,ご興味がある方は是非ご連絡ください.
References
- Hermans, Beyer, and Leibe. (2017) In defense of the triplet loss for person reidentification. arXiv preprint arXiv:1703.07737
- Chen, Deng, and Du. (2017) Noisy Softmax: Improving the Generalization Ability of DCNN via Postponing the Early Softmax Saturation. In CVPR pp. 5372-5381
- Su, Li, Zhang, Xing, Gao, and Tian. (2002) Pose-driven Deep Convolutional Model for Person Reidentification. In ICCV pp. 3960-3969
- Song, Huang, Ouyang, and Wang. (2018) Mask-guided contrastive attention model for person reidentification. In CVPR pp. 1179-1188
- Wang, Zhang, Huang, Liu, and Wang. (2018) Mancs: A multitask attentional network with curriculum sampling for person reidentification. In ECCV pp. 384-400
- Cheng, Gong, Zhou, Wang, and Zheng. (2016) Person Re-Identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function. In CVPR pp. 1335-1344
- Li, Chen, Zhang, and Huang. (2017) Learning Deep Context-aware Features over Body and Latent Parts for Person Reidentification. In CVPR pp. 384-393
- Yi, Lei, Liao, and Li. (2014) Deep Metric Learning for Person Reidentification. In International Conference on Pattern Recognition pp. 34-39
- Chen, Xu, Li, Sebe, and Wang. (2018) Group Consistent Similarity Learning via Deep CRF for Person ReIdentification. In CVPR pp. 8649-8658
- Ahmed, Jones, and Marks. (2015) An improved deep learning architecture for person reidentification. In CVPR pp. 3908-3916
- Hoffer and Ailon. (2015) Deep Metric Learning Using Triplet Network. In International Workshop on Similarity Based Pattern Recognition pp. 84-92
- Ristani, Solera, Zou, Cucchiara, and Tomasi. (2002) Performance Measures and a Data Set for Multitarget, Multicamera Tracking. In ECCV pp. 17-35
- Schroff, Kalenichenko, and Philbin. (2015) FaceNet: A Unified Embedding for Face Recognition and Clustering. In CVPR pp. 815-823
- Yang, Yan, Lu, Jia, Xie, and Gao. (2019) Attention driven person reidentification. In CVPR pp. 143-155
- Wang, Yang, Liu, Wang, Yang, Wang, Yu, Zhou and Sun. (2020) High Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification. In CVPR pp. 6449-6458
- Wang, Y.Yuan, Chen, Li, Zhou. (2018) Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In ICME pp. 274-282
- Liu, Feng, Qi, Jiang, and Yan. (2019) Deep Residual Network with Self Attention Improves Person Re-Identification Accuracy. In ICMLC pp. 380-385
- Yao, Zhang, Zhang, Li, and Tian. (2019) Deep Representation Learning With Part Loss for Person Re-Identification. In Transactions on Image Processing pp. 2860-2871
- Zhao, Tian, Sun, Shao, Yan, Yi, Wang. (2017) Person Reidentification with Human Body Region Guided Feature Decomposition and Fusion. In CVPR pp. 907-915
- Liu, Feng, Qi, Jiang, and Yan. (2018) End-to-end comparative attention networks for person reidentification. In Transactions on Image Processing pp. 3492-3506
- Almazan, Gajic, Murray, and Larlus. (2018) ReID done right: towards good practices for person reidentification. arXiv preprint arXiv:1801.05339
- Deng, Dong, Socher, L.J. Li, Li, and FeiFei. (2009) ImageNet: A largescale hierarchical image database. In CVPR pp. 248-255
- Xu, Zhao, Zhu, Wang, and Ouyang. (2018) Attention-aware compositional network for person reidentification. In CVPR pp. 2119-2128
- Si, Zhang, Li, Kuen, Kong, Kot. (2018) Dual attention matching network for context aware feature sequence-based person reidentification. In CVPR pp. 5363-5372
- Kingma Ba, Adam: (2015) A Method for Stochastic Optimization. In ICLR pp. 3192-4001
- Chen, Deng, and Hu. (2019) Mixed high order attention network for person reidentification. In ICCV pp. 371-381
- Sohn. (2016) Improved Deep Metric Learning with Multiclass Npair Loss Objective. In Neural Information Processing Systems pp. 1857-1865
- Zhou, Yang, Cavallaro, and T Xiang. (2019) Omni-scale feature learning for person reidentification. In ICCV pp. 3701-3711
- Zhao, Li, Wang, and Zhuang. (2017) Deeply Learned Part Aligned Representations for Person Re-Identification. In ICCV pp. 3219-3228
- Zheng, Shen, Tian, Wang, Wang, and Tian. (2015) Scalable person reidentification: A benchmark. In ICCV pp. 1116-1124
- Wei, Zhang, Gao and Tian. (2018) Person Transfer GAN to Bridge Domain Gap for Person Reidentification. In CVPR pp. 7988 -8002
- Kalayeh, Basaran, okmen, Kamasak, and Shah. (2018) Human semantic parsing for person reidentification. In CVPR pp. 1062-1071
- Sarfraz, Schumann, Eberle, and Stiefelhagen. (2018) Pose-Sensitive Embedding for Person Re-Identification with Expanded Cross Neighborhood Re-Ranking. In CVPR pp. 420-429
- Felzenszwalb, McAllester, and Ramanan. (2008) A discriminatively trained, multiscale, deformable part model. In CVPR 18
- Fang, Zhou, Kumar Roy, Petersson, and Harandi. (2019) Bilinear attention networks for person retrieval. In ICCV pp. 8030-8039
- Hadsell, Chopra, and LeCun. (2006) Dimensionality Reduction by Learning an Invariant Mapping. In CVPR pp. 1735-1742
- Hou, Ma, Chang, Gu, Shan, and X Chen. (2020) Interaction and aggregation network for person reidentification. In CVPR pp. 9317-9326
- Selvaraju, Cogswell, Das, Parikh, and Batra. (2017) Gradcam: Visual explanations from deep networks via gradient based localization. In ICCV pp. 618-626
- Ioffe and Szegedy. (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. In ICML pp. 448-456
- Woo, Park, Lee, and Kweon. (2018) Cbam: Convolutional block attention module. In ECCV pp. 319 -325
- Xiao, Li, Ouyang, and Wang. (2016) Learning Deep Feature Representations with Domain Guided Dropout for Person Reidentification. In CVPR pp. 1249-1258
- Chen, Chen, Zhang, and Huang. (2017) Beyond Triplet Loss: A Deep Quadruplet Network for Person Reidentification. In CVPR pp. 1320-1329
- Li, Zhao, Xiao, and Wang. (2014) DeepReID: Deep Filter Pairing Neural Network for Person Reidentification. In CVPR pp. 152-159
- Li, Zhu, and Gong. (2017) Person reidentification by deep joint learning of multiloss classification. In International Joint Conference on Artificial Intelligence pp. 2194-2200
- Li, Zhu, and Gong. (2018) Harmonious Attention Network for Person Re-Identification. In CVPR pp. 2285-2294
- Bai, Yang, Huang, Dou, Yu, and Xu. (2018) DeepPerson: Learning Discriminative Deep Features for Person Re-Identification. arXiv:1711.10658
- Chang, Hospedales, and Xiang. (2018) Multilevel Factorisation Net for Person Reidentification. In CVPR pp. 2109-2118
- Liu, Zhao, Tian, Sheng, Shao, Yi, Yan, and Wang. (2017) HydraPlusNet: Attentive Deep Features for Pedestrian Analysis. In ICCV 19
- Qian, Fu, Wang, Xiang, Wu, Y.G. Jiang, and Xue. (2018) Pose-Normalized Image Generation for Person Reidentification. In ECCV pp. 661-678
- Zhang, Luo, Fan, Xiang, Sun, Xiao, Jiang. (2017) Aligned ReID: Surpassing Human Level Performance in Person Re-Identification. arXiv:1711.08184
- Chen, Fu, Zhao, Zheng, Song, Ji, Yang. (2020) Salience Guided Cascaded Suppression Network for Person Reidentification. In CVPR pp. 3300-3310
- Chen, Zhu, and Gong. (2017) Person Reidentification by Deep Learning Multiscale Representations. In Conference on Computer Vision Workshops pp. 2590-2600
- Zhang, Xiang, T.Hospedales, Lu. (2018) Deep Mutual Learning. In CVPR pp. 4320-4328
- Sun, Zheng, Deng, and Wang. (2017) SVDNet for Pedestrian Retrieval. In ICCV pp. 3820-3828
- Sun, Zheng, Yang, Tian, and Wang. (2018) Beyond Part Models: Person Retrieval with Refined Part Pooling. In ECCV pp. 234-778
- Wen, Zhang, Li, and Qiao. (2016) A Discriminative Feature Learning Approach for Deep Face Recognition. In ECCV pp. 499-515
- Fu, Wei, Zhou, Shi, Huang, Wang, Yao, and Huang. (2019) Horizontal pyramid matching for person reidentification. In AAAI pp. 8295-8302
- Shen, Li, Xiao, Yi, Chen, and Wang. (2018) Deep Group Shuffling Random Walk for Person Re-Identification. In CVPR pp. 2265-2274
- Sun, Wang, and Tang. (2015) Deeply learned face representations are spars. In CVPR pp. 2892-2900
- Zheng, Zheng, and Yang. (2018) Pedestrian alignment network for largescale person reidentification. In TCSVT pp. 3037-3045
- Zheng, Zheng, and Yang. (2017) Unlabeled Samples Generated by GAN Improve the Person Reidentification Baseline in Vitro. In ICCV pp. 3774-3782
- Zhong, Zheng, Cao, and Li. (2017) Reranking Person Reidentification with k Reciprocal Encoding. In CVPR pp. 3652-3661
- Zheng, Yang, Yu, Zheng, Yang, and Kautz. (2019) Joint discriminative and generative learning for person reidentification. In ICCV pp. 2138-2147
- Zheng, Yang, Yu, Zheng, Yang, and Kautz. (2019) Densely semantically aligned person reidentification. In ICCV pp. 667-676
- Zhang, Lan, Zeng, Jin, Chen. (2020) Relation Aware Global Attention for Person Reidentification. In CVPR pp. 3186-3195