こんにちは.株式会社Ridge-iの@zawatsky_rと@machinery81です. 本記事ではPruningと呼ばれるニューラルネットワークの軽量化手法を紹介します.
- TL;DR
- Pruningとは?
- Pruningに関する論文の紹介
- Pruningツールの紹介
- Pruningに関するチュートリアル資料
- さいごに
- 参考文献
TL;DR
- ニューラルネットワークのモデル圧縮アプローチの一つであるPruningの概要を紹介
- Pruningの各手法ごとの主な違いを紹介
- Pruningに関する論文について,有名なものから最新のものまでのサマリーを作成
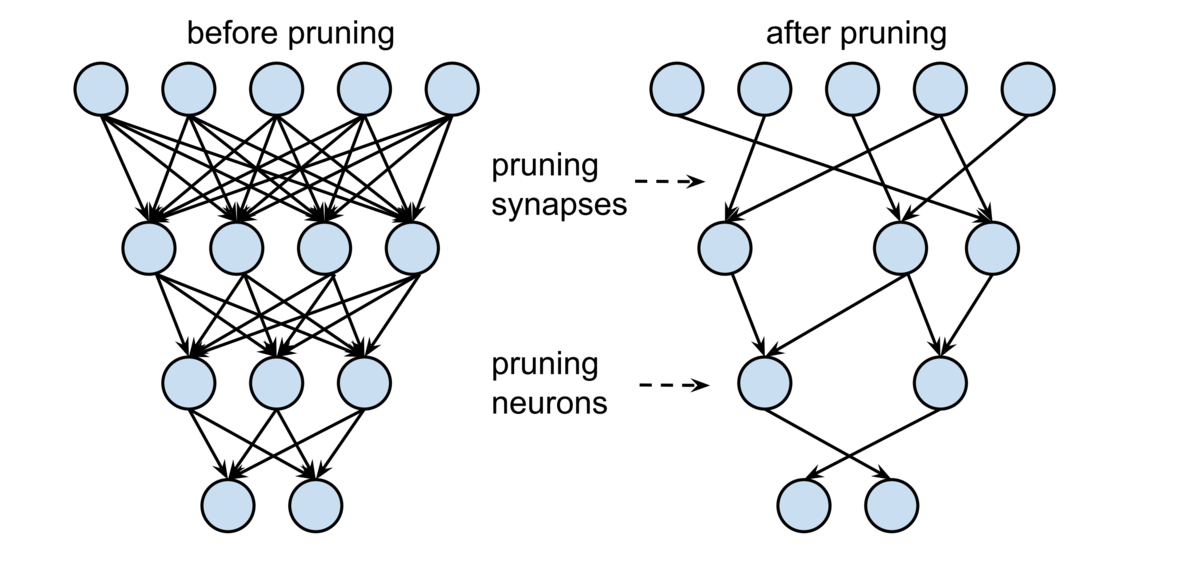
Pruningとは?
深層学習は画像認識や音声認識などの分野において,既存手法を上回る精度を達成しています.一方,学習プロセスにおいては膨大な演算処理を行う必要があり,演算に多大な時間を要することや,ハードウェアのメモリ容量の限界といった課題があります.また,昨今のモデルの大規模化,入力データの高解像度化,エッジデバイスなどへの適用など,演算時間の短縮と演算時のメモリ削減の需要は高まっています. こうした課題を解決するための一つの手法として,ニューラルネットワークの重みの一部を取り除く(値を0にする)ことでパラメータ数や計算量を削減するNeural Network Pruningと呼ばれる手法が提案されています.
1980年代後半にPruningが提案されて以来,Pruningに関する論文数は年々増加しています.

Pruning手法の概要
Pruningは,ニューラルネットワークの学習時に行われるものと,推論時に行われるものがあります.ニューラルネットワークの学習時に行われるPruningの多くは[Han et al., 2015]の手法に由来しており,主に以下の流れで学習が行われます.
- ネットワークが収束するまで学習
- ネットワークのパラメータ(重みなど)のスコアに基づきネットワークをPruning
- Pruning後のネットワークで再学習

Pruningに期待される効果には,メモリ使用量の削減,計算量の削減,計算エネルギー削減があります.しかし,計算効率化の達成と精度の達成はしばしばトレードオフの関係にあることが観測されており,このトレードオフを改善するために様々な手法が研究されています,
手法の違いのポイント
2020年のメタ研究 [Blalock et al., 2020]では,これまで提案されてきたPruning手法の主な違いとして以下の4点をあげています.
- Structure
- Scoring
- Scheduling
- Fine-Tuning
Structure
一つ目の違いは,Pruning後のネットワークが持つ構造の規則性にあります.Pruning手法は,Pruningするネットワークの構成要素の単位によって大きく2つに分類でき,重み単位での不規則なPruningをUnstructured Pruning(非構造的Pruning),層やフィルタ単位での規則性を持ったPruningをStructured Pruning(構造的Pruning)といいます.
既存のGPUライブラリを使用する場合,Structureの違いにおいて,演算効率性と精度はトレードオフの関係にあることが観測されています.Unstructured Pruningを高速化するためには,カスタマイズしたハードウェアが必要となる場合が多くあります.一方のStructured Pruningは,既存のGPUライブラリでも演算効率性を高めることができますが,精度はUnstructured Pruningと比較して低くなる傾向があります.
 ※ 汎用ハードウェアにおいて,既存の演算ライブラリを使用した場合.
※ 汎用ハードウェアにおいて,既存の演算ライブラリを使用した場合.
Scoring
二つ目の違いは,Pruning対象となる要素を選択するための基準です.重みの絶対値(またはその合計値)が低いものからPruningする方法や,学習された重要度係数,勾配などへの貢献度に基づいてPruningする手法など,Pruningの対象を決めるための様々なスコアリング方法があります.
また,要素間のスコアの比較方法には,層ごとに比較するものや,ネットワーク全体で比較するものがあります.
Scheduling
三つ目の違いとして,学習の中でのPruningのタイミングやその回数があります.定めたPruning率になるように,1度のステップで必要な重みを全てPruningする手法,反復的に同じ数の重みをPruningする手法,徐々にPruningする重みの数を減らしていく手法などがあります.
Fine-Tuning
最後に,Pruningされたネットワークの再学習方法も手法によって異なります.[Han et al., 2015]の手法のように,Pruning前の学習済の重みを使用してネットワークを再学習するものがあるほか,学習の過程でPruningしたネットワークの重みの値をランダムな初期値にして再学習する手法 [Liu et al,. 2019]や,学習前の初期値に戻してから再学習を行う手法 [Frankle et al,. 2019]があります.
そのほか,学習前の初期化時に一度だけネットワークをPruningする手法の研究[Lee et al,. 2019]や,初期化時に学習せずにスパースな学習可能なサブネットワークを特定できるかという問いに対する研究[Tanaka et al,. 2020]も行われています.
Pruningに関する論文の紹介
以下ではPruningに関する論文を紹介していきます.
Unstructured Pruning
Unstructured Pruning(非構造的Pruning)は,重み単位での不規則なPruning手法です.Pruningの対象を決めるためのScoringとして,重みの絶対値の値が小さい方からPruningをするMagnitude Pruningと呼ばれる手法があります.そのほか,変分ドロップアウトを拡張した手法 [Molchanov et al., 2017]や,L_0ノルム正則化を適用する手法 [Louizos et al., 2018]も提案されています.
Magnitude Pruningの場合,ネットワーク全体で小さい重みから順番にPruningするよりも,層ごとに小さい重みから順番にPruningする方が良い実験結果が得られています.また,各学習ステップでPruningする重みの数は,学習率に合わせて,徐々に小さくしていく方が精度劣化を防げることも観測されています.[Zhu et al., 2018, Gale et al., 2019]
Unstructured Pruningは,既存のマルチコアCPU やGPUといった汎用ハードウェアでの演算高速化は困難であり,演算の高速化にはカスタマイズされたハードウェアがしばしば必要となります. 最近になって,Unstructured Pruningの演算を高速化するためのGPUカーネルの研究も行われ始めています.[Gale et al., 2020, Wang, 2020]
Structured Pruning
Unstructured Pruningは,汎用ハードウェアでの演算高速化が困難であるというハードルがありました.しかし,このためにカスタマイズされたハードウェアを作ることはコストがかかることから,やはり汎用ハードウェアでPruningを実現したいところです.そこで,汎用ハードウェアでの高速化を実現するため,Unstructured Pruningよりも粗い単位で規則的にPruningするStructured Pruning(構造的Pruning)が研究されています.Structured Pruningでは,層やフィルタ単位といったある塊でのPruningが行われます.Structured Pruningにより疎となったネットワークの行列演算は,既存のGPUライブラリでも高速化することが可能です.

しかし,前述のとおり,Structured PruningはUnstructured Pruningと比較して精度劣化を起こしやすいと観測されています.この精度劣化を防ぎながらネットワークを圧縮するための手法が様々提案されており,例えば,Neuron Merging [Kim et al., 2020]は,Pruningされたフィルタの情報を別のフィルタに結合することで情報の損失を防ぐことで,この問題に取り組んでいます.Neuron Mergingの研究では,単純なフィルタ単位のPruningよりも精度劣化を防ぎながら,ネットワークを軽量化できることを実験から示しています.

自動モデル圧縮
機械学習において自動でハイパーパラメータチューニングを達成するAutoMLのフレームワークで,Pruningを含めたモデル圧縮を自動で行うことを目指す研究も多く存在します. これは,ただでさえ膨大な機械学習アルゴリズムのハイパーパラメータのチューニングに加えて,そうして学習されるニューラルネットワークの軽量化手続きまで人間が手動で調整するのはあまりに大変なのではないかというモチベーションが背景にあります. 実際,手動でのチューニング作業が増えると,その技術が社会に浸透するまでにかかる時間も増えてしまうので,なるべく人間が触るインターフェースはシンプルにしつつ,内部で自動で所望のモデルが獲得できる仕組みは非常に意義があるものと思われます.
Amc: AutoML for Model Compressionとその亜種
自動モデル圧縮の手法のうち,後続の手法群の先駆けとなった研究にAmc [Yihui et al., 2018]があります.この論文はECCV2018に採択されており,その他のAutoML手法の多くと同じように強化学習ベースでモデル圧縮の問題に取り組んでいます.本手法の内部では強力な強化学習手法であるDDPG [David et al., 2015]を採用し,実験的に良好な性能を報告しています.

後続の研究としては,[Tianzhe et al., 2020]や[Chaopeng et al., 2020]などがあり,今後も発展していくコンセプトの一つであると予想できそうです.
また,ニューラルネットワークの軽量化の手段はPruningだけに限られず,他にも量子化やそもそも軽量なネットワーク構造の採用なども考えられ,これらを組み合わせることでそれぞれを単体で行うよりも大きな効果が期待できます.Apq [Chaopeng et al., 2020]は,そのようなPruningおよび量子化戦略と軽量な構造探索を自動で行うことを提案しています.
AutoPruner
AutoPruner [Jian-Hao et al., 2020]は,Pruning先のネットワークにPruningを実行するレイヤーを追加する形でこの問題に取り組んでいます.この手法ではどれだけネットワークの軽量化を目指すかに当たる圧縮レートも自動で決定することを提案しています.
また,一般的なPruningのようになんらかの指標によって重要なチャンネルを選択し,そうでないチャンネルを枝刈りするという方針ではなく,最初からPruningされた軽量なネットワーク構造を構造探索するアプローチも研究されています [Mingbao et al., 2020].これは,所与のネットワーク構造から不要なチャンネルを削除するという操作が性能の劣化を引き起こしやすいという観測から,直接軽量な構造を作ってしまおうという動機に基づいています.
上記のような自動Pruningで獲得されるニューラルネットワークは軽量なだけでなく,時にPruningなしのモデルを上回る性能を達成できる場合もあることが報告されています.例えばAutoPrunerと同様の構造探索型の自動Pruning手法であるMetaPruning [Zechun et al., 2019]では,非常に人気なネットワーク構造であるMobile Net v2において,提案手法によって探索された軽量なニューラルネットワークが元々のネットワークの性能を上回るケースがあることを実験結果から示しています.

The Lottery Ticket Hypothesis
一般的な共通認識として,ニューラルネットワークが大規模であるほど表現力が高く,良い性能を達成しやすいというものがあると思います. 一方で,これまで紹介してきたニューラルネットワークのPruningの研究をおさらいすると,必ずしも大きいニューラルネットワークが常に最良であるとは限らず,むしろ不要なニューロンをPruningしてコンパクトにしたネットワークの方が性能が高い場合すらあります. ここでニューラルネットワークが大規模であることと良い性能を達成できることの関係性についてある仮説が立てられます:
大規模なニューラルネットワークが高性能を達成しやすいのは,くじをたくさん引いているからではないか?
ここで当たりくじに該当するのが良い性能を達成できるニューラルネットワークの構造です.つまり,タスクに応じて当たりくじに当たるような良い部分ネットワーク構造が存在し,大規模なニューラルネットワークは部分構造をたくさん含むため,そのような当たりくじを引きやすいのではないかという仮説です.

この仮説はThe Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks [Frankle et al., 2019]によって提唱され,この論文はICLR2019のBest Paper Awardに選出されています. このコンセプトは非常に面白く,後続の研究も数多く公開されています:
- Brix, Christopher, Parnia Bahar, and Hermann Ney. "Successfully applying the stabilized lottery ticket hypothesis to the transformer architecture." arXiv preprint arXiv:2005.03454 (2020).
- Frankle, Jonathan, et al. "Linear mode connectivity and the lottery ticket hypothesis." International Conference on Machine Learning. PMLR, 2020.
- Malach, Eran, et al. "Proving the lottery ticket hypothesis: Pruning is all you need." International Conference on Machine Learning. PMLR, 2020.
- Chen, Tianlong, et al. "The lottery ticket hypothesis for pre-trained bert networks." arXiv preprint arXiv:2007.12223 (2020).
- Frankle, Jonathan, et al. "Stabilizing the lottery ticket hypothesis." arXiv preprint arXiv:1903.01611 (2019).
- Zhou, Hattie, et al. "Deconstructing lottery tickets: Zeros, signs, and the supermask." arXiv preprint arXiv:1905.01067 (2019).
- Yu, Haonan, et al. "Playing the lottery with rewards and multiple languages: lottery tickets in rl and nlp." arXiv preprint arXiv:1906.02768 (2019).
メタ研究
個別の要素技術の研究だけでなく,その分野そのものに関するメタ研究も非常に重要な研究の方向性の一つです. 例えば,ヒューリスティクスに比較実験が行われがちな分野にしっかりとしたベンチマークや実験方法を提供したり,そもそも当時有効だと報告されていた研究が今現在どれだけ有意義なものなのかを検証したりする研究がこれにあたります.
To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression
[Zhu et al., 2017]では,大規模なネットワークをPruningしたモデルと,小規模で密なネットワークのモデルでは,モデルの精度とネットワークサイズのトレードオフにおいてどちらが有用なのか,という問に答えるため,それぞれのネットワークの比較実験を行っています.比較実験の結果,Pruningされた大規模なネットワークの方が,小規模で密なネットワークと同等もしくは高い精度を達成することを報告しています.
また,この実験と併せて,学習中にPruningのスケジューリングを自動で行うアルゴリズムも提案しています.
Rethinking the Value of Network Pruning
多くのPruning手法は,Pruningを適用した上で学習済の重みを引き継いで再学習をする方法を採用していますが,[Liu et al., 2017]では,Pruningが適用されたネットワークの重みをランダムな値に初期化して学習した方が,学習済の重みを引き継いで再学習する方法と比べて同等または高い精度を達成することを実験から示しています.この主張は,Pruningされた大規模なモデルは,小さなネットワークアーキテクチャのモデルで代替可能であること,大規模モデルで学習された重みは,Pruning後のモデルではそこまで有用ではないことを意味します.
また,ランダムな初期値を採用する手法でも,Lottery TicketのようにPruning後に学習前の初期値に戻してから再学習する手法は,Pruning後にランダムな値に初期化して学習する方法による精度を上回らないことも実験から示しています.
しかしながら,次に紹介するメタ研究ではこの研究結果とは異なる主張がなされています.
The State of Sparsity in Deep Neural Networks
これまで数多くのPruning手法が提案されてきましたが,各論文の評価時のタスクが標準化されておらず,各手法の相対的な評価が困難であるという課題があります. [Trevor et al., 2019]は,自然言語と画像認識タスクにおける大規模学習タスクで,3つの代表的な手法(Variational Dropout [Molchanov et al., 2017], L0 Regularization [Louizos et al., 2018], Magnitude Pruning [Zhu et al,. 2018])の有効性の検証を行っています.この検証から,TransformerやResNet-50を扱う大規模な学習タスクの場合,これまで小規模な学習では有用であることが示されていたVariational Dropout,L0 RegularizationよりもMagnitude Pruningの方が有用であることを報告しています.
さらにこの研究では,先に紹介した[Frankle et al,. 2018]や[Liu et al 2017]の主張「学習済の重みではなくランダムな初期値または学習前の初期値を用いることでより高い精度が得られる」に関して大規模学習タスクにおいて実験を行っており,実験から,大規模学習タスクでは,Unstructured Pruningが適用されたネットワークをスクラッチから学習しても,学習済の重みを引き継いで再学習したPruningモデルの精度には至らないことを報告しています.

What is the State of Neural Network Pruning?
これまでPruning手法は数多く提案されてきましたが,過去または最新のモデルとの比較が不十分,データセットやネットワークアーキテクチャ,ハイパーパラメータの設定が論文ごとに異なる,評価手法や実験結果の表示方法が揃っていないなど,評価時のベンチマーク方法の標準化が行われておらず各手法の横比較が難しいという課題があります.
この課題に取り組むため,[Blalock et al., 2020]は81の論文の結果の網羅的な分析を行った上で,Pruning手法の評価を標準化するための以下のような実験フレームワークを提案しています:
- アーキテクチャ,データセット,評価手法の正確な組み合わせを明示
- データセットとアーキテクチャについて少なくとも3つの組み合わせでの比較を実施
- 圧縮率と高速化の定義を明確化
- ImageNetや多クラスデータセットでは,Top-1及びTop-5の精度を報告
- 各データセット/アーキテクチャのペアごとに,比較手法と合わせて精度-圧縮率のトレードオフ曲線を描画
- 精度-圧縮率のトレードオフ曲線をプロットする際には,圧縮率の範囲にまたがる少なくとも5つの動作点{2, 4, 8, 16, 32}を描画
サーベイ論文
Pruningに関するサーベイ論文を紹介しておきます.これらは全体を俯瞰するために非常に有用であり,それぞれの技術を詳しく掘り下げていく前に抑えておく価値があると思います.
- Liang, Tailin, et al. "Pruning and Quantization for Deep Neural Network Acceleration: A Survey." arXiv preprint arXiv:2101.09671 (2021).
- Xu, Sheng, et al. "Convolutional Neural Network Pruning: A Survey." 2020 39th Chinese Control Conference (CCC). IEEE, 2020.
- Liu, Jiayi, et al. "Pruning Algorithms to Accelerate Convolutional Neural Networks for Edge Applications: A Survey." arXiv preprint arXiv:2005.04275 (2020).
- Cheng, Yu, et al. "A survey of model compression and acceleration for deep neural networks." arXiv preprint arXiv:1710.09282 (2017).
Pruningのこれからの話題
今まで多くの分野で活躍してきたニューラルネットワークは,畳み込み構造を持ったCNNでした.当然ながら,Pruningの多くの研究もこのCNNの軽量化に焦点が当てられているものが非常に多いです.
しかしながら,2021年になって新たに注目されているネットワーク構造としてTransformerがあり,非常に大きな期待を寄せられています. 現在Transformerが期待されている理由としては,様々なタスクで高性能を達成できているだけでなく,OpenAIが発表した以下の論文が示す結果に由来するものも少なからずあります:
- Kaplan, Jared, et al. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).
この論文内では,Transformerの性能はデータセットサイズ,パラメータ数,計算資源を増やし続ければ際限なく向上し続けるということを示唆しています.

この結果は非常に驚異的なものですが,同時にボトルネックの存在も示唆します. 上記の結果は,経済力がモデルの性能も決めてしまうという事実に等しいですが,超大規模な計算資源を用意できるテックジャイアントならいざ知らず,その他の中・小規模な大学や研究機関および企業では,必ず上記3つの要素それぞれでいずれ限界に直面します. ところで,Pruningの役割はニューラルネットワークの不要な重みを削除することでパラメータ数と計算資源を削減することでした.もしPruningによってTransformerのScaling Lawに従いつつモデルの軽量化を達成できれば,このようなボトルネックを緩和できる可能性があります.
実際,TransformerにPruningを適用した結果がすでにいくつか報告されています:
- Li, Bingbing, et al. "Efficient Transformer-based Large Scale Language Representations using Hardware-friendly Block Structured Pruning." arXiv preprint arXiv:2009.08065 (2020).
- Brix, Christopher, Parnia Bahar, and Hermann Ney. "Successfully applying the stabilized lottery ticket hypothesis to the transformer architecture." arXiv preprint arXiv:2005.03454 (2020).
- Lin, Zi, et al. "Pruning Redundant Mappings in Transformer Models via Spectral-Normalized Identity Prior." arXiv preprint arXiv:2010.01791 (2020).
これまでも,計算資源の差で達成できるモデルの性能にも差は出ていましたが,今後より高度なタスクをより発展したモデルで解くことが主流になると,計算資源レースに追従できない組織はそうしたタスクに取り組むことさえできないという状況になってしまうかもしれません.Neural Network Pruningはディープラーニング技術の民主化のために今後さらに必須となる技術になるかもしれません.
Pruningツールの紹介
現在ニューラルネットワークを記述するのに人気のフレームワークにおいてPruningを簡単に実行するためのサードパーティライブラリも存在します.
import torch from torchvision.models import resnet18 import torch_pruning as tp model = resnet18(pretrained=True) # 1. setup strategy (L1 Norm) strategy = tp.strategy.L1Strategy() # or tp.strategy.RandomStrategy() # 2. build layer dependency for resnet18 DG = tp.DependencyGraph() DG.build_dependency(model, example_inputs=torch.randn(1,3,224,224)) # 3. get a pruning plan from the dependency graph. pruning_idxs = strategy(model.conv1.weight, amount=0.4) # or manually selected pruning_idxs=[2, 6, 9] pruning_plan = DG.get_pruning_plan( model.conv1, tp.prune_conv, idxs=pruning_idxs ) print(pruning_plan) # 4. execute this plan (prune the model) pruning_plan.exec()
Keras-surgeon
from kerassurgeon.operations import delete_layer, insert_layer, delete_channels # delete layer_1 from a model model = delete_layer(model, layer_1) # insert new_layer_1 before layer_2 in a model model = insert_layer(model, layer_2, new_layer_3) # delete channels 0, 4 and 67 from layer_2 in model model = delete_channels(model, layer_2, [0,4,67])
nnplot

Photo by https://github.com/yuvalailer/nnplot
Pruningに関するチュートリアル資料
Pruningに関するチュートリアル資料も紹介しておきます. 特にニューラルネットワークに関連する技術は,自身で動かすことが容易な時代になってきており,実際に動作を確認しておくことで仕組みの理解の助けになると思います.
さいごに
Ridge-iでは様々なポジションで積極採用中です. カジュアル面談も可能ですので,ご興味がある方は是非ご連絡ください.
参考文献
- Liang, Tailin, et al. "Pruning and Quantization for Deep Neural Network Acceleration: A Survey." arXiv preprint arXiv:2101.09671 (2021).
- Kaplan, Jared, et al. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).
- Li, Bingbing, et al. "Efficient Transformer-based Large Scale Language Representations using Hardware-friendly Block Structured Pruning." arXiv preprint arXiv:2009.08065 (2020).
- Brix, Christopher, Parnia Bahar, and Hermann Ney. "Successfully applying the stabilized lottery ticket hypothesis to the transformer architecture." arXiv preprint arXiv:2005.03454 (2020).
- Lin, Zi, et al. "Pruning Redundant Mappings in Transformer Models via Spectral-Normalized Identity Prior." arXiv preprint arXiv:2010.01791 (2020).
- Xu, Sheng, et al. "Convolutional Neural Network Pruning: A Survey." 2020 39th Chinese Control Conference (CCC). IEEE, 2020.
- Liu, Jiayi, et al. "Pruning Algorithms to Accelerate Convolutional Neural Networks for Edge Applications: A Survey." arXiv preprint arXiv:2005.04275 (2020).
- Zhang, Chaopeng, Yuesheng Zhu, and Zhiqiang Bai. 2020. “MetaAMC: Meta Learning and AutoML for Model Compression.” In Twelfth International Conference on Digital Image Processing (ICDIP 2020), 11519:115191U. International Society for Optics and Photonics.
- Wang, Tianzhe, Kuan Wang, Han Cai, Ji Lin, Zhijian Liu, Hanrui Wang, Yujun Lin, and Song Han. 2020. “Apq: Joint Search for Network Architecture, Pruning and Quantization Policy.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2078–87. openaccess.thecvf.com.
- Luo, Jian-Hao, and Jianxin Wu. 2020. “AutoPruner: An End-to-End Trainable Filter Pruning Method for Efficient Deep Model Inference.” Pattern Recognition 107 (November): 107461.
- E M Mirkes, "Artificial Neural Network Pruning to Extract Knowledge," 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 2020, pp. 1-8, doi: 10.1109/IJCNN48605.2020.9206861.
- Blalock, D., Ortiz, J. J. G., Frankle, J., & Guttag, J. "What is the state of neural network pruning?." arXiv preprint arXiv:2003.03033 (2020).
- Tanaka, H., Kunin, D., Yamins, D. L., & Ganguli, S. Pruning neural networks without any data by iteratively conserving synaptic flow. arXiv preprint arXiv:2006.05467 (2020)
- Kim, W., Kim, S., Park, M., & Jeon, G. Neuron Merging: Compensating for Pruned Neurons. Advances in Neural Information Processing Systems 33. 2020.
- Lin, Mingbao, Rongrong Ji, Yuxin Zhang, Baochang Zhang, Yongjian Wu, and Yonghong Tian. 2020. “Channel Pruning via Automatic Structure Search.” arXiv [cs.CV]. arXiv. http://arxiv.org/abs/2001.08565.
- Brix, Christopher, Parnia Bahar, and Hermann Ney. "Successfully applying the stabilized lottery ticket hypothesis to the transformer architecture." arXiv preprint arXiv:2005.03454 (2020).
- Frankle, Jonathan, et al. "Linear mode connectivity and the lottery ticket hypothesis." International Conference on Machine Learning. PMLR, 2020.
- Malach, Eran, et al. "Proving the lottery ticket hypothesis: Pruning is all you need." International Conference on Machine Learning. PMLR, 2020.
- Wang, Z. SparseRT: Accelerating Unstructured Sparsity on GPUs for Deep Learning Inference. In Proceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques (pp. 31-42), 2020.
- Trevor Gale, Matei Zaharia, Cliff Young, and Erich Elsen. 2020. Sparse GPU Kernels for Deep Learning. arXiv preprint arXiv:2006.10901 (2020).
- Chen, Tianlong, et al. "The lottery ticket hypothesis for pre-trained bert networks." arXiv preprint arXiv:2007.12223 (2020).
- Gale, Trevor, Erich Elsen, and Sara Hooker. "The state of sparsity in deep neural networks." arXiv preprint arXiv:1902.09574 (2019).
- Frankle, Jonathan, et al. "Stabilizing the lottery ticket hypothesis." arXiv preprint arXiv:1903.01611 (2019).
- Zhou, Hattie, et al. "Deconstructing lottery tickets: Zeros, signs, and the supermask." arXiv preprint arXiv:1905.01067 (2019).
- Yu, Haonan, et al. "Playing the lottery with rewards and multiple languages: lottery tickets in rl and nlp." arXiv preprint arXiv:1906.02768 (2019).
- Lee, N., Ajanthan, T., and Torr, P. H. S. Snip: singleshot network pruning based on connection sensitivity. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6- 9, 2019.
- Liu, Z., Sun, M., Zhou, T., Huang, G., and Darrell, T. Rethinking the value of network pruning. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019.
- Frankle, J. and Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019.
- Liu, Zechun, et al. "Metapruning: Meta learning for automatic neural network channel pruning." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
- He, Yihui, et al. "Amc: Automl for model compression and acceleration on mobile devices." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
- Christos Louizos, Max Welling, and Diederik P. Kingma. Learning sparse neural networks through l0 regularization. In International Conference on Learning Representations, 2018.
- Zhu, M. and Gupta, S. To prune, or not to prune: exploring the efficacy of pruning for model compression. ICLR Workshop, 2018.
- Cheng, Yu, et al. "A survey of model compression and acceleration for deep neural networks." arXiv preprint arXiv:1710.09282 (2017).
- Molchanov, D., Ashukha, A., and Vetrov, D. Variational dropout sparsifies deep neural networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 2498–2507. JMLR. org, 2017.
- H Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf. Pruning filters for efficient convnets. In ICLR, 2017.
- Han, S., Pool, J., Tran, J., and Dally, W. Learning both weights and connections for efficient neural network. In Advances in neural information processing systems, pp. 1135–1143, 2015.
- Silver, David, et al. "Deterministic policy gradient algorithms." International conference on machine learning. PMLR, 2014.